
一个优秀的RPC框架,流量控制是必不可少的功能之一。
在上一篇文章聊聊服务注册与发现中,我们讲了微服务架构中核心功能之一服务注册与发现。在本文中,我们将着重讲下微服务的另外一个核心功能点:流量控制。
在微服务系统中,整个系统是以一系列固有功能的微服务组成,如果某一个服务,因为流量异常或者其他原因,导致响应异常,那么同样的也会影响到调用该服务的其他服务,从而引起了一系列连锁反应,最终导致整个系统崩溃。针对此种问题,我们在之前的文章微服务架构之雪崩效应有讲解过解决方案,今天我们针对方案中的限流控制来进行深入讲解。
限流这件事,对于微服务架构来说,最直接的就是跟系统承载能力正相关。任何系统都有它服务能力上限,如果在请求链路上,某个子服务的请求量超过其承载能力,那么该链路上的请求将无法正常响应,而此时,如果在client端对于不能返回的请求不断重试(retry),那么对原本已经超过负载上限的子服务来说,无异于雪上加霜。而这一的模式在拖垮了链路上的某个子服务后,可能会影响到其上游服务,导致影响范围持续扩大,进而让其它原本正常的服务也跟着失效,从而引起雪崩,雪崩效应会加速整个系统无法提供服务。
解决这个问题的方式,就是限流。如果监测到这个现象时候(错误率增高,rt变大或者是服务负载高于其安全阈值),就直接开启某些策略,在服务负载恢复前,丢弃新的request,以使得整个系统安全可靠。这个就是限流的目的。不过,这个机制困难的不在于要挑选哪种框架或者给某个服务来使用,而是是否有办法精准掌握系统内各个子服务的负载上限,并且有能力做好整合,进一步做到自动化调节限流策略。
在解释什么是限流之前,我们先了解一个点,就是服务的请求上限,也可以理解为是服务承载量,即该服务支持一定时间内最多能够支持多少请求。只有将服务承载量进行量化,能够被测量,才能根据这个测量值,采取一定的对应措施。
服务承载量,指的是单位时间内的处理量。北京地铁早高峰,地铁站都会做一件事情,就是限流了!想法很直接,就是想在一定时间内把请求限制在一定范围内,保证系统不被冲垮,同时尽可能提升系统的吞吐量。
再以我家里的带宽为例,是联通100m的,也就是说,每一秒钟,联通提供最大100m bits的数据传输量。那么联通是如何限制这个上限的呢?假如我是联通,可能有以下几个方面:
看到上面这些方案,就会发现,做到真正的限制,不是那么容易的。因为每一个方案实现原理都不同,也就意味着代码实现不同。
现在,假如我们使用方案2来实现,等真正测试或者上线后,会崩溃吧,因为流量控制根本不是像我们预期的那样进行控制,这是因为重新计算流量的过程有可能已经超了0.01ns。显然要尽可能精准的控制流量,需要回答下面两个问题:
显然,我们在想清楚上面两个问题后,实现方案基本就能定下来了。收到了新的request,只要确认目前的服务是否还有能力处理这个request即可。这个时候流量是直接丢弃,还是返回其他值,根据具体情况进行具体分析。
限流常用的方式有:
下面我将深入讲解上述的四种限流方式,先讲解原理,然后是实现,最后分析其特点。
确定方法的最大访问量MAX,每次进入方法前计数器+1,将结果和最大并发量MAX比较,如果大于等于MAX,则直接返回;如果小于MAX,则继续执行。
计数器的实现方式,简单粗暴。在一段时间内,进行计数,与阀值进行比较,到了时间临界点,将计数器清0。

在上图中,我们以1分钟即60秒为一个时间片,在该时间片内最多处理请求为1000,如果超过了上限,则拒绝服务(具体依赖于实际业务场景)。
我们将计数器的思路在明确下就是:
针对上面的计数器原理,代码实现如下:
class CounterController {
public:
CounterController(int max, int duration) {
max_ = max;
duration_ = duration;
last_update_time_ = time(nullptr);
}
bool IsValid() {
uint64_t now = time(nullptr);
if (now < last_update_time_ + duration_) {
++req_num_;
return max_ > req_num_;
} else {
last_update_time_ = now;
req_num_ = 1;
return max_ > req_num_;
}
}
private:
int max_;
int duration_;
int last_update_time_;
int req_num_ = 0;
};
在实现代码中,其中有四个成员变量:
其中,计数器限流方案的实现是在成员函数IsValid()中实现的,即为该次请求是否有效。在该函数中,我们首先判断当前时间戳与上次更新时间戳之差是否超过了时间片,如果当前时间戳处于上次更新后的时间片内,则请求数+1,然后判断请求数是否超过了该时间片的处理上限。如果不处于上次更新后的时间片内,则重置更新时间以及请求数。
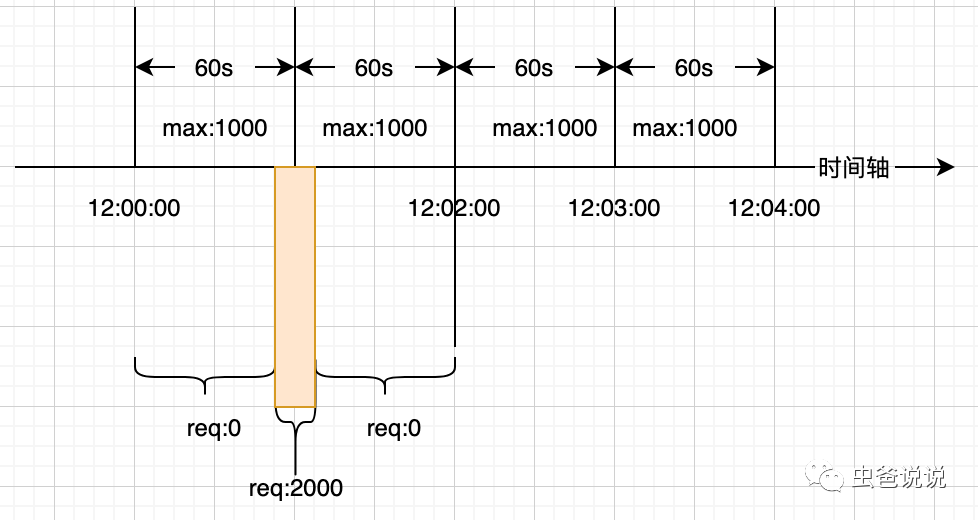
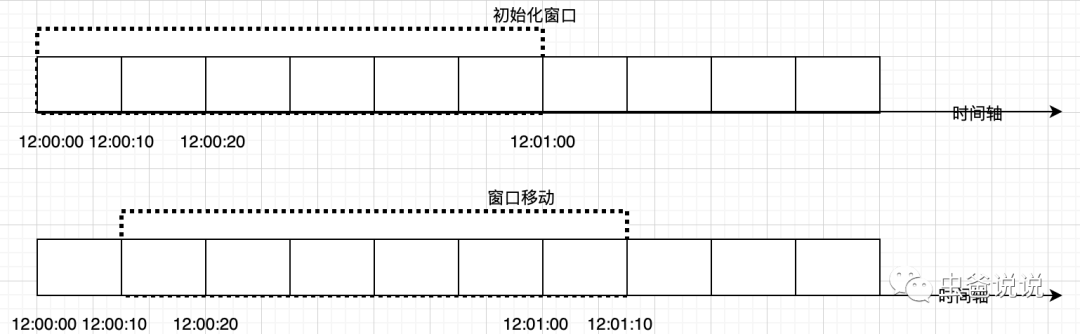
计数器滑动窗口算法是计数器固定窗口算法的改进,解决了固定窗口切换时可能会产生两倍于阈值流量请求的缺点。
滑动窗口的意思是说把固定时间片,进行划分,并且随着时间的流逝,进行移动,这样就巧妙的避开了计数器的临界点问题。也就是说这些固定数量的可以移动的格子,将会进行计数判断阀值,因此格子的数量影响着滑动窗口算法的精度。
在TCP中,也使用了滑动窗口来进行网络流量控制,感兴趣的同学可以阅读TCP之滑动窗口原理。
计数器方式是一种特殊的滑动窗口,其窗口大小为1个时间片;
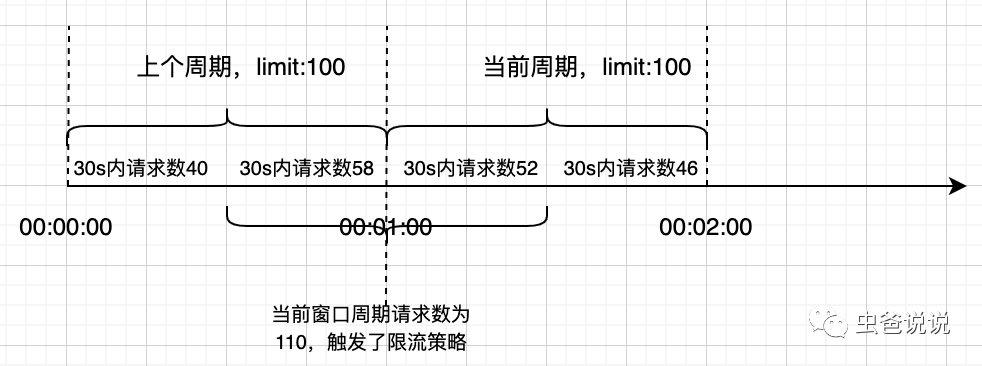
滑动窗口算法在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。同时要保证整个窗口中所有小窗口的请求数目之后不能超过设定的阈值。
class SlidingWindowController {
public:
SlidingWindowController(int window_size, int limit, int split_num) {
limit_ = limit;
window_size_ = window_size;
counters_.resize(split_num);
split_num_ = split_num;
}
int IsValid() {
uint64_t now_ms = 0;
GetCurrentTimeMs(&now_ms);
int window_num = std::max(now_ms - window_size_ - start_time_, 0) / (window_size_ / split_num_);
SlidingWindow(window_num);
int count = 0;
for(int i = 0;i < split_num_; ++i){
count += counters_[i];
}
if(count >= limit){
return false;
}else{
counters_[index] ++;
return true;
}
return true;
}
private:
void SlidingWindow(int window_num) {
if (window_num == 0) {
return;
}
int slide_num = std::min(window_num, split_num_);
for (int i = 0; i < slide_num; ++i) {
index_ = (index_ + 1) % split_num;
counters_[index_] = 0;
}
start_time_ = start_time_ + wind_num * (window_size_ / split_num_); // 更新滑动窗口时间
}
int window_size_; // 窗口大小,单位为毫秒
int limit_; // 窗口内限流大小
std::vector<int> counters_;
uint64_t start_time_; // 窗口开始时间
int index_ = 0; // 当前窗口计时器索引
int split_num_;
};
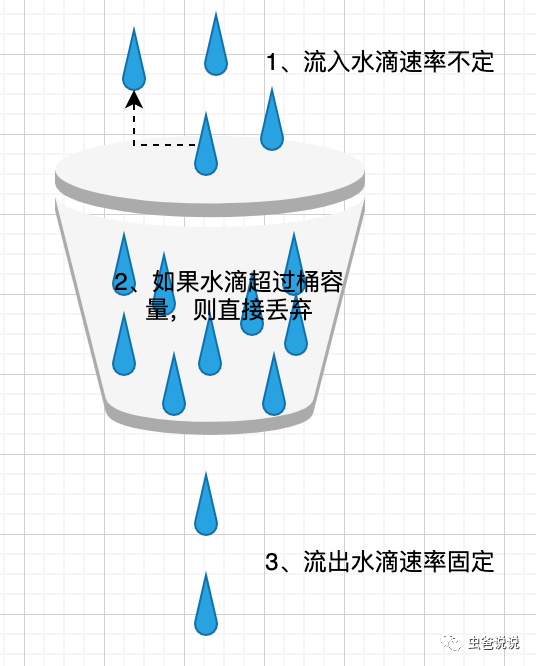
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
以固定速率从桶中流出水滴,以任意速率往桶中放入水滴,桶容量大小是不会发生改变的。
流入:以任意速率往桶中放入水滴。
流出:以固定速率从桶中流出水滴。
因为桶中的容量是固定的,如果流入水滴的速率>流出的水滴速率,桶中的水滴可能会溢出。那么溢出的水滴请求都是拒绝访问的,或者直接调用服务降级方法。前提是同一时刻。
但是对于很多场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
请求来了之后会首先进到漏斗里,然后漏斗以恒定的速率将请求流出进行处理,从而起到平滑流量的作用。当请求的流量过大时,漏斗达到最大容量时会溢出,此时请求被丢弃。从系统的角度来看,我们不知道什么时候会有请求来,也不知道请求会以多大的速率来,这就给系统的安全性埋下了隐患。但是如果加了一层漏斗算法限流之后,就能够保证请求以恒定的速率流出。在系统看来,请求永远是以平滑的传输速率过来,从而起到了保护系统的作用。
class LeakyBucketController {
public:
LeakyBucketController(int rate) {
capacity_ = rate;
last_update_time_ = time(nullptr);
}
bool IsValid() {
// 计算这段时间,漏了多少水
uint64_t now = time(nullptr);
int out = (new - last_update_time_) * rate;
if (out > 0) {
last_update_time_ = now;
}
// 计算桶中剩余的水
water_ = std::max(0, water_ - out);
// 如果桶没有满,则表示有效
if (water_ < capacity_) {
++water_;
return true;
}
return false;
}
private:
int capacity_;
int water_ = 0;
uint64_t last_update_time_;
};
漏桶的漏出速率是固定的 由于漏出速率固定,因此即使流量流入速率不定,但是经过漏斗之后,变成了有固定速率的稳定流量,可以对下游系统起到保护作用
不能解决流量突发的问题。假设我们设置漏斗速率为10个/秒,桶的容量为50个。此时突然来了100个请求,那么只有50个请求被接收,另外50个被拒绝。这个时候,你可能会认为瞬间接受了50个请求,不就解决了流量突发问题么?不,这50个请求只是被接受了,但是没有马上被处理,处理的速度仍然是我们设定的10个/秒,所以没有解决流量突发的问题。而接下来我们要谈的令牌桶算法能够在一定程度上解决流量突发的问题。
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
令牌桶算法是以恒定的速率将令牌放入桶中,这个时候如果来了突发流量,如果桶中有令牌,则可以直接获取令牌,并处理请求,基于该原理,就解决了漏桶算法中不能 处理突发流量 的问题。
在令牌桶算法中,令牌以恒定速率放入桶中。桶也有一定的容量,如果满了令牌就无法放进去了。当请求来了之后,会受限到桶中去拿令牌,如何取到了令牌,则该请求被处理,并消耗掉拿到的令牌,否则,该请求被丢弃。
class TokenBucketController {
public:
TokenBucketController(int num, uint64_t duration) :
duration_(duration), rate_(num > 0 ? (num / duration_ / 1000) : 0),
limit_(num), modulo_(num > 0 ?(num % (duration * 1000)) : 0) {
GetCurrentTimeMs(&last_update_time_);
::curr_idx = 0;
}
bool IsValid();
private:
void Update();
const uint64_t duration_;
const int rate_;
const int limit_;
const uint64_t modulo_;
uint64_t last_update_time_;
uint64_t loss_ = 0;
uint64_t counts_ = 0;
};
void TokenBucketController::Update() {
uint64_t cur_time_ms;
GetCurrentTimeMs(&cur_time_ms);
uint64_t time_passed_since_last_update = cur_time_ms - last_update_time_;
if (time_passed_since_last_update == 0) {
return;
}
if (counts_ == static_cast<uint64_t>(limit_)) {
last_update_time_ = cur_time_ms;
return;
}
uint64_t count_to_add = rate_ * time_passed_since_last_update;
loss_ += modulo_ * time_passed_since_last_update;
if (loss_ >= duration_ * 1000) {
count_to_add += loss_ / duration_ / 1000;
loss_ %= (duration_ * 1000);
}
counts_ += count_to_add;
if (counts_ > static_cast<uint64_t>(limit_)) {
counts_ = limit_;
}
last_update_time_ = cur_time_ms;
}
bool TokenBucketController::IsValid() {
if (limit_ < 0) {
return true;
}
if (counts_ >= 1) {
counts_ -= 1;
return true;
}
Update();
if (counts_ >= 1) {
counts_ -= 1;
return true;
}
return false;
}
在实现上,令牌桶跟漏桶的区别,是一个控制进,一个控制出。在InValid函数中,先判断桶中是否有令牌,如果有则返回true,否则,进行更新桶中令牌(Update函数),然后再进行判断是否有令牌可用。
令牌桶算法来作为限流,在业界使用最多,除了能够在限制调用的平均速率的同时还允许一定程度的流量突发。
下面我们把本文中的四种限流策略做下简单对比,来作为对本文的一个总结。计数器算法:该算法实现简单,容易理解。但是在时间片切换时刻,容易出现两倍于阈值的流量,也可以说是滑动窗口算法的简版(窗口只有一个)。
滑动窗口算法:解决了计数器算法中的2倍阈值的问题,其流量控制精度依赖于窗口个数,窗口个数越多,精度控制越准。
漏桶算法:以任意速率往桶中放入水滴,如果桶中的水滴没有满的话,可以访问服务,不能处理突发流量。
令牌桶算法:以固定的速率(平均速率)生成对应的令牌放到桶中,客户端只需要在桶中获取到令牌后,就可以访问服务请求,与漏桶算法相比,其可以处理一定的突发流量。
令牌桶算法是通过控制令牌生成的速度进行限流,
漏桶算法是控制请求从桶中流出的速度进行限流。
简单理解为:令牌桶控制进,漏桶控制出。
如果要让自己的系统不被打垮,用令牌桶。如果保证被别人的系统不被打垮,用漏桶算法。
以上四种限流算法都有自身的特点,具体使用时还是要结合自身的场景进行选取,没有最好的算法,只有最合适的算法。比如令牌桶算法一般用于保护自身的系统,对调用者进行限流,保护自身的系统不被突发的流量打垮。如果自身的系统实际的处理能力强于配置的流量限制时,可以允许一定程度的流量突发,使得实际的处理速率高于配置的速率,充分利用系统资源。而漏斗算法一般用于保护第三方的系统,比如自身的系统需要调用第三方的接口,为了保护第三方的系统不被自身的调用打垮,便可以通过漏斗算法进行限流,保证自身的流量平稳的打到第三方的接口上。
算法是死的,而算法中的思想精髓才是值得我们学习的。实际的场景中完全可以灵活运用,还是那句话,没有最好的算法,只有最合适的算法。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板