
从网卡到应用程序,数据包会经过一系列组件,其中驱动做了什么?内核做了什么?为了优化,我们又能做些什么?整个过程中涉及到诸多细微可调的软硬件参数,并且相互影响,不存在一劳永逸的“银弹”。本文中又拍云系统开发高级工程师杨鹏将结合自己的的实践经验,介绍在深入理解底层机制的基础上如何做出“场景化”的最优配置。
文章根据杨鹏在又拍云 Open Talk 技术沙龙北京站主题演讲《性能优化:更快地接收数据》整理而成,现场视频及 PPT 可点击阅读原文查看。
大家好,我是又拍云开发工程师杨鹏,在又拍云工作已有四年时间,期间一直从事 CDN 底层系统开发的工作,负责调度、缓存、负载均衡等 CDN 的核心组件,很高兴来跟大家分享在网络数据处理方面的经验和感受。今天分享的主题是《如何更快地接收数据》,主要介绍加速网络数据处理的方法和实践。希望能帮助大家更好的了解如何在系统的层面,尽量在应用程序无感的情况下做到极致的优化。言归正传,进入主题。
首先需要清楚在尝试做任何优化的时候,想到的第一件事情应该是什么?个人觉得是衡量指标。做任何改动或优化之前,都要明确地知道,是怎样的指标反映出了当前的问题。那么在做了相应的调整或改动之后,也才能通过指标去验证实际效果与作用。
针对要分享的主题,有一个围绕上面指标核心的基本原则。在网络层面做优化,归根结底只需要看一点,假如可以做到网络栈的每个层次,加入能监控到对应层次的丢包率,这样核心的指标,就可以明确地知道问题出在哪一层。有了明确可监控的指标,之后做相应的调整与实际效果的验证也就很简单了。当然上述两点相对有点虚,接下来就是比较干的部分了。

如上图所示,当收到一个数据包,从进入网卡,一直到达应用层,总的数据流程有很多。在当前阶段,无需关注每个流程,留意其中几个核心的关键路径即可:
第一个,数据包到达网卡;
第二个,网卡在收到数据包时,它需要产生一个中断,告诉 CPU 数据已经到了;
第三步,内核从这个时候开始进行接管,把数据从网卡中拿出来,交到后面内核的协议栈去处理。
以上是三个关键的路径。上图中右边的手绘图指的就是这三个步骤,并有意区分了两个颜色。之所以这么区分是因为接下来会按这两部分进行分享,一是上层驱动部分,二是下层涉及到内核的部分。 当然内核比较多,通篇只涉及到内核网络子系统,更具体来说是内核跟驱动交互部分的内容。
网卡驱动的部分,网卡是硬件,驱动(driver)是软件,包括了网卡驱动部分的大部分。这部分可简单分四个点,依次是初始化、启动、监控与调优驱动它的初始化流程。
网卡驱动-初始化
驱动初始化的过程和硬件相关,无需过分关注。但需注意一点就是注册 ethool 的一系列操作,这个工具可以对网卡做各种各样的操作,不止可以读取网卡的配置,还可以更改网卡的配置参数,是一个非常强大的工具。
那它是如何控制网卡的呢?每个网卡的驱动在初始化时,通过接口,去注册支持 ethool 工具的一系列操作。ethool 是一套很通用的接口,比如说它支持 100 个功能,但每个型号的网卡,只能支持一个子集。所以具体支持哪些功能,会在这一步进行声明。

上图截取的部分,是在初始化时结构体的赋值。前面两个可以简单看一下,驱动在初始化的时候会告诉内核,如果想要操作这块网卡对应的回调函数,其中最主要的是启动和关闭,有用 ifconfig 工具操作网卡的应该都很熟悉,当用 ifconfig up/down 一张网卡的时候,调用的都是它初始化时指定的这几个函数。
网卡驱动-启动
驱动初始化过程之后就是启动(open)中的流程了,一共分为四步:分配 rx/tx 队列内存、
开启 NAPI、注册中断处理函数、开启中断。其中注册中断处理函数和开启中断是理所当然的,任何一个硬件接入到机器上都需要做这个操作。当后面收到一些事件时,它需要通过中断去通知系统,然后开启中断。
第二步的 NAPI 后面会详细说明,这里先重点关注启动过程中对内存的分配。网卡在收到数据时,都必须把数据从链路层拷贝到机器的内存里,而这块内存就是网卡在启动时,通过接口向内核、向操作系统申请而来的。内存一旦申请下来,地址确定之后,后续网卡在收到数据的时候,就可以直接通过 DMA 的机制,直接把数据包传送到内存固定的地址中去,甚至不需要 CPU 的参与。
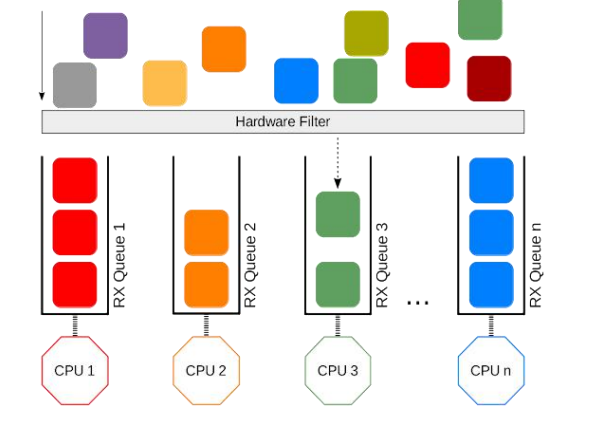
到队列内存的分配可以看下上图,很早之前的网卡都是单队列的机制,但现代的网卡大多都是多队列的。好处就是机器网卡的数据接收可以被负载均衡到多个 CPU 上,因此会提供多个队列,这里先有个概念后面会详细说明。
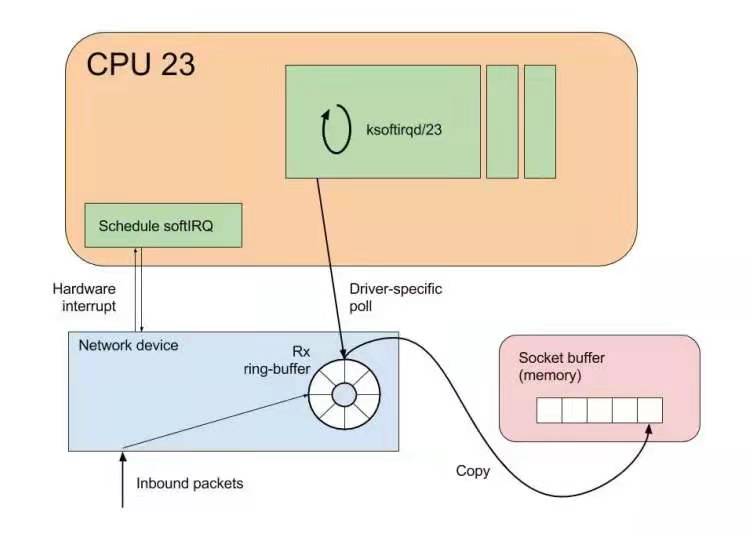
下面来详细介绍启动过程中的第二步 NAPI,这是现代网络数据包处理框架中非常重要的一个扩展。之所以现在能支持 10G、20G、25G 等非常高速的网卡,NAPI 机制起到了非常大的作用。当然 NAPI 并不复杂,其核心就两点:中断、轮循。一般来说,网卡在接收数据时肯定是收一个包,产生一个中断,然后在中断处理函数的时候将包处理掉。处在收包、处理中断,下一个收包,再处理中断,这样的循环中。而 NAPI 机制优势在于只需要一次中断,收到之后就可以通过轮循的方式,把队列内存中所有的数据都拿走,达到非常高效的状态。
网卡驱动-监控
接下来就是在驱动这层可以做的监控了,需要去关注其中一些数据的来源。
$ sudo ethtool -S eth0
NIC statistics:
rx_packets: 597028087
tx_packets: 5924278060
rx_bytes: 112643393747
tx_bytes: 990080156714
rx_broadcast: 96
tx_broadcast: 116
rx_multicast:20294528
....
首先非常重要的是 ethool 工具,它可以拿到网卡中统计的数据、接收的包数量、处理的流量等等常规的信息,而我们更多的是需要关注到异常信息。
$ cat /sys/class/net/eth0/statistics/rx_dropped
2
通过 sysfs 的接口,可以看到网卡的丢包数,这就是系统出现异常的一个标志。

三个途径拿到的信息与前面差不多,只是格式有些乱,仅做了解即可。
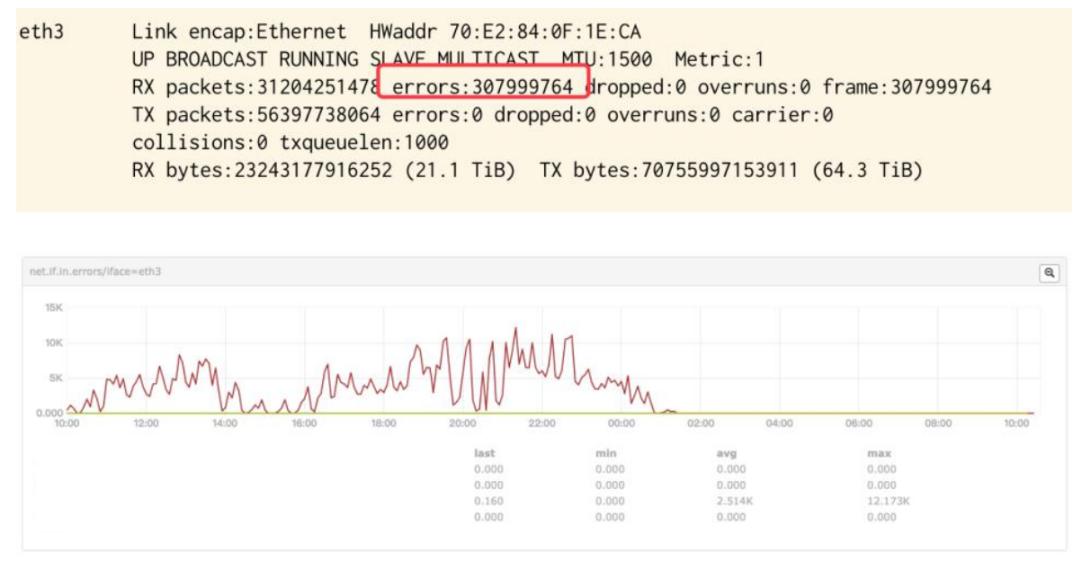
上图是要分享的一个线上案例。当时业务上出现异常,经过排查最后是怀疑到网卡这层,为此需要做进一步的分析。通过 ifconfig 工具可以很直观的查看到网卡的一些统计数据,图中可以看到网卡的 errors 数据指标非常高,明显出现了问题。但更有意思的一点是, errors 右边最后的 frame 指标数值跟它完全相同。因为 errors 指标是网卡中很多错误累加之后的指标,与它相邻的 dropped、overruns 这俩个指标都是零,也就是说在当时的状态下,网卡的错误大部分来自 frame。
当然这只是瞬时的状态,上图中下面部分是监控数据,可以明显看到波动的变化,确实是某一台机器异常了。frame 错误一般是在网卡收到数据包,进行 RCR 校验时失败导致的。当收到数据包,会对该包中的内容做校验,当发现跟已经存下来的校验不匹配,说明包是损坏的,因此会直接将其丢掉。
这个原因是比较好分析的,两点一线,机器的网卡通过网线接到上联交换机。当这里出现问题,不是网线就是机器本身的网卡问题,或者是对端交换机的端口,也就是上联交换机端口出现问题。当然按第一优先级去分析,协调运维去更换了机器对应的网线,后面的指标情况也反映出了效果,指标直接突降直到完全消失,错误也就不复存在了,对应上层的业务也很快恢复了正常。
网卡驱动-调优
说完监控之后来看下最后的调优。在这个层面能调整的东西不多,主要是针对网卡多队列的调整,比较直观。调整队列数目、大小,各队列间的权重,甚至是调整哈希的字段,都是可以的。
$ sudo ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 8
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 4
上图是针对多队列的调整。为了说明刚才的概念,举个例子,比如有个 web server 绑定到了 CPU2,而机器有多个 CPU,这个机器的网卡也是多队列的,其中某个队列会被 CPU2 处理。这个时候就会有一个问题,因为网卡有多个队列,所以 80 端口的流量只会被分配到其中一个队列上去。假如这个队列不是由 CPU2 处理的,就会涉及到一些数据的腾挪。底层把数据接收上来后再交给应用层的时候,需要把这个数据移动一下。如果本来在 CPU1 处理的,需要挪到 CPU2 去,这时会涉及到 CPU cache 的失效,这对高速运转的 CPU 来说是代价很高的操作。
那么该怎么做呢?我们可以通过前面提到的工具,特意把 80 端口 tcp 数据流量导向到对应 CPU2 处理的网卡队列。这么做的效果是数据包从到达网卡开始,到内核处理完再到送达应用层,都是同一个 CPU。这样最大的好处就是缓存,CPU 的 cache 始终是热的,如此整体下来,它的延迟、效果也会非常好。当然这个例子并不实际,主要是为了说明能做到的一个效果。
说完了整个网卡驱动部分,接下来是讲解内核子系统部分,这块会分为软中断与网络子系统初始化两部分来分享。
软中断

上图的 NETDEV 是 linux 网络子系统每年都会开的一个分会,其中比较有意思的点是每年大会举办的届数会以一个特殊字符来表示。图中是办到了 0X15 届,想必也都发现这是 16 进制的数字,0X15 刚好就是 21 年,也是比较极客范。对网络子系统感兴趣的可以去关注一下。
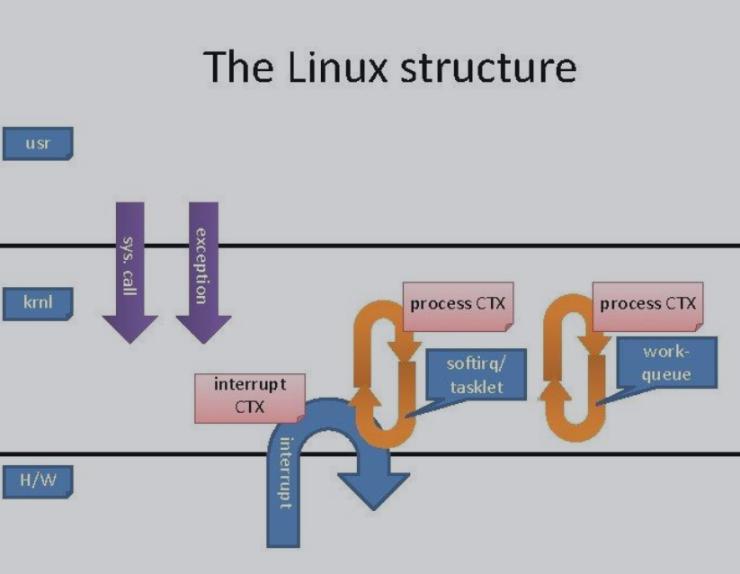
言归正传,内核延时任务有多种机制,而软中断只是其中一种。上图是 linux 的基本结构,上层是用户态,中间是内核,下层是硬件,很抽象的一个分层。用户态和内核态之间会有两种交互的方式:通过系统调用,或者通过异常可以陷入到内核态里面。那底层的硬件跟内核又是怎么交互的呢?答案是中断,硬件跟内核交互的时候必须通过中断,处理任何事件都需要产生一个中断信号来告知 CPU 与内核。
不过这样的机制一般情况下也许没有问题,但是对网络数据来说,一个数据报一个中断,这样会有很明显的两个问题。
问题一:中断在处理期间,会屏蔽之前的中断信号。当一个中断处理的时间很长,在处理期间收到的中断信号都会丢掉。 如果处理一个包用了十秒,在这十秒期间又收到了五个数据包,但因为中断信号丢了,即便前面的处理完了,后面的数据包也不会再处理了。对应到 tcp 这边,假如客户端给服务端发了一个数据包,几秒后处理完了,但在处理期间客户端又发了后续的三个包,但是服务端后面并不知道,以为只收到了一个包,这时客户端又在等待服务端的回包,如此会导致两边都卡住了,也说明了信号丢失是一个极其严重的问题。
问题二:一个数据包触发一次中断处理的话,当有大量的数据包到来后,就会产生非常大量的中断。 如果达到了 10 万、50 万、甚至百万的 pps,那 CPU 就需要处理大量的网络中断,也就不用干其他事情了。
而针对以上两点问题的解决方法就是让中断处理尽可能的短。 具体来说,不能在中断处理函数,只能把它揪出来,交到软中断机制里。这样之后的实际结果是硬件的中断处理做的事情就很少了,将接收数据等一些必须的事情交到软中断去完成,这也是软中断存在的意义。
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread-comm = “ksoftirqd/%u”,
};
static _init int spawn_ksoftirqd(void)
{
regiter_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
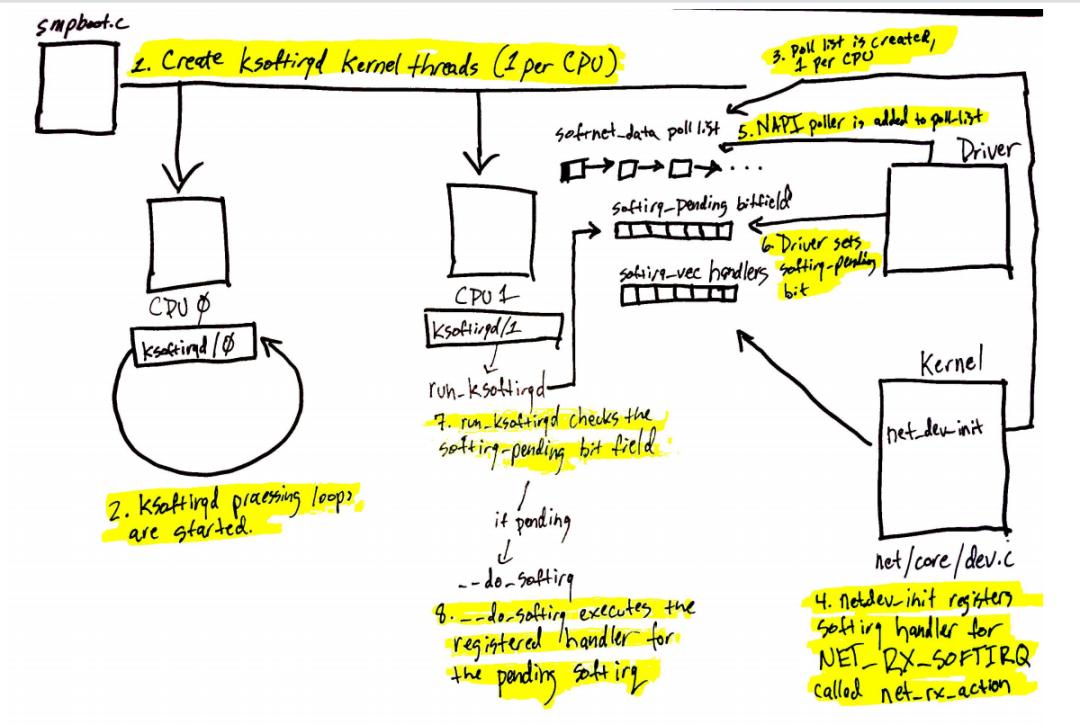
软中断机制是通过内核的线程来实现的。图中是对应的一个内核线程。服务器 CPU 都会有一个 ksoftirqd 这样的内核线程,多 CPU 的机器会相对应的有多个线程。图中结构体最后一个成员 ksoftirqd/,如果有三个 CPU 对应就会有 /0/1/2 三个内核线程。
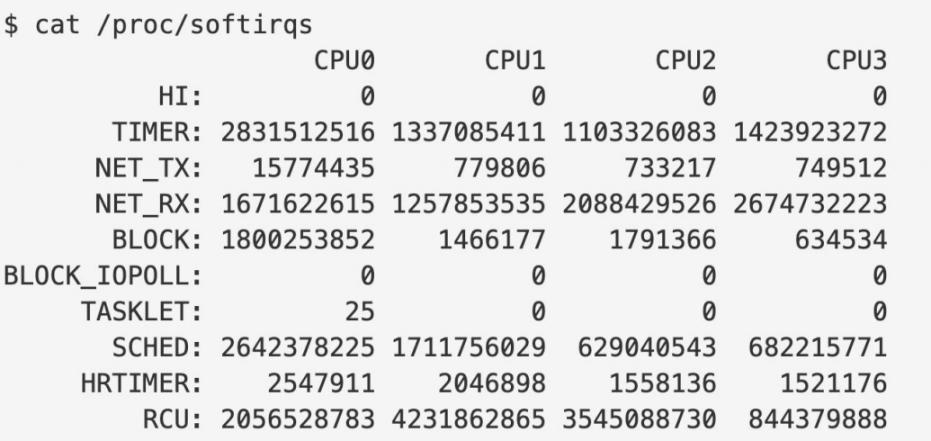
软中断机制的信息在 softirqs 下面可以看到。软中断并不多只有几种,其中需要关注的,跟网络相关的就是 NET-TX 和 NET-RX,网络数据收发的两种场景。
内核初始化
铺垫完软中断之后,下面来看内核初始化的流程。主要为两步:
针对每个 CPU,创建一个数据结构,这上面挂了非常多的成员,与后面的处理密切相关;
注册一个软中断处理函数,对应上面看到的 NET-TX 和 NET-RX 这两个软中断的处理函数。
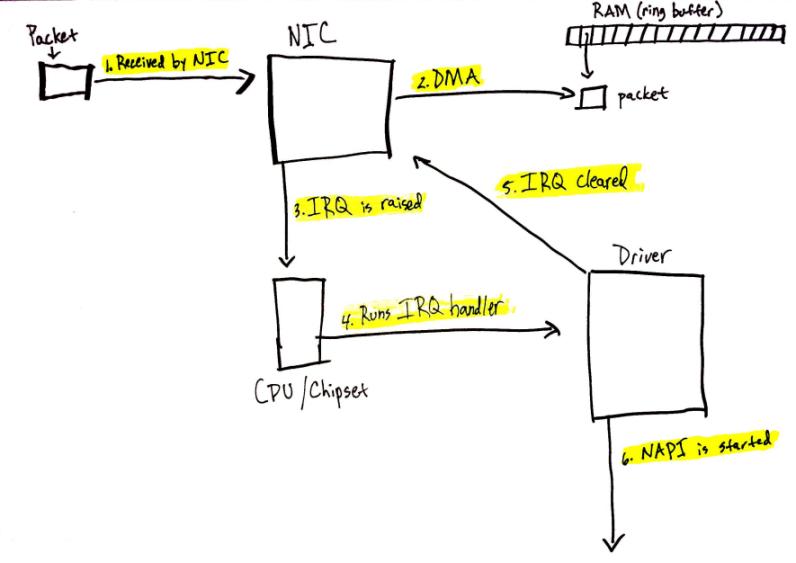
上图是手绘的一个数据包的处理流程:
第一步网卡收到了数据包;
第二步把数据包通过 DMA 拷到了内存里面;
第三步产生了一个中断告诉 CPU 并开始处理中断。重点的中断处理可分为两步:一是将中断信号屏蔽了,二是唤醒 NAPI 机制。
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRO_HANDLED;
}
上面的代码是 igb 网卡驱动中断处理函数做的事情。如果省略掉开始的变量声明和后面的返回,这个中断处理函数只有两行代码,非常短。需要关注的是第二个,在硬件中断处理函数中,只用激活外部 NIPA 软中断处理机制,无需做其他任何事情。因此这个中断处理函数会返回的非常快。
NIPI 激活
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
_raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
NIPI 的激活也很简单,主要为两步。内核网络系统在初始化的时每个 CPU 都会有一个结构体,它会把队列对应的信息插入到结构体的链表里。换句话说,每个网卡队列在收到数据的时候,需要把自己的队列信息告诉对应的 CPU,将这两个信息绑定起来,保证某个 CPU 处理某个队列。
除此之外,还要与触发硬中断一样,需要触发软中断。下图将很多步骤放到了一块,前面讲过的就不再赘述了。图中要关注的是软中断是怎么触发的。与硬中断差不多,软中断也有中断的向量表。每个中断号,都会对应一个处理函数,当需要处理某个中断,只需要在对应的中断向量表里找就好了,跟硬中断的处理是一模一样的。
数据接收-监控
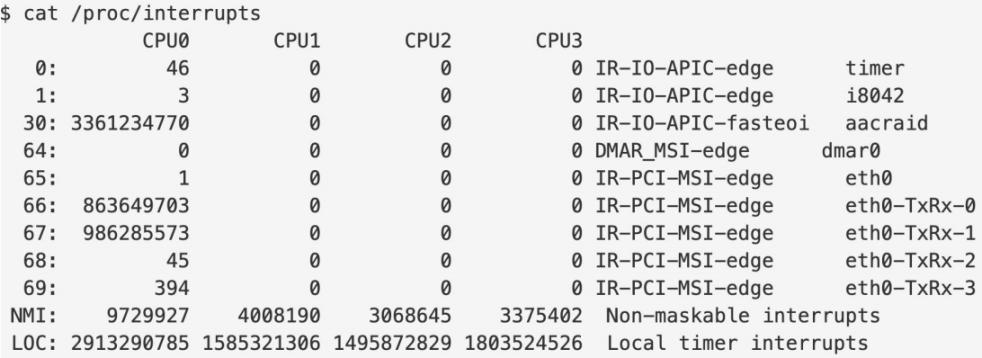
说完了运作机制,再来看看有哪些地方可以做监控。在 proc 下面有很多东西,可以看到中断的处理情况。第一列就是中断号,每个设备都有独立的中断号,这是写死的。对网络来说只需要关注网卡对应的中断号,图中是 65、66、67、68 等。当然看实际的数字并没有意义,而是需要看它的分布情况,中断是不是被不同 CPU 在处理,如果所有的中断都是被一个 CPU 处理,那么就需要做些调整,把它分散开。
数据接收-调优
中断可以做的调整有两个:一是中断合并,二是中断亲和性。
自适应中断合并
rx-usecs: 数据帧到达后,延迟多长时间产生中断信号,单位微秒
rx-frames: 触发中断前积累数据帧的最大个数
rx-usecs-irq: 如果有中断处理正在执行,当前中断延迟多久送达 CPU
rx-frames-irq: 如果有中断处理正在执行,最多积累多少个数据帧
上面列的都是硬件网卡支持的功能。NAPI 本质上也是中断合并的机制,假如有很多包的到来,NAPI 就可以做到只产生一个中断,因此不需要硬件来帮助做中断合并,实际效果是跟 NAPI 是相同的,都是减少了总的中断数量。
中断亲和性
$ sudo bash -c ‘echo 1 > /proc/irq/8/smp_affinity’
这个与网卡多队列是密切相关的。如果网卡有多个队列,就能手动来明确指定由哪个 CPU 来处理,均衡的把数据处理的负载分散到机器的可用 CPU 上。配置也比较简单,只需把数字写入到 /proc 对应的这个文件中就可以了。这是个位数组,转成二进制后就会有对应的 CPU 去处理。如果写个 1,可能就是 CPU0 来处理;如果写个 4,转化成二进制是 100,那么就会交给 CPU2 去处理。
另外有个小问题需要注意,很多发行版可能会自带一个 irqbalance 的守护进程(http://irqbalance.github.io/irqbalance),会将手动中断均衡的设置给覆盖掉。这个程序做的核心事情就是把上面手动设置文件的操作放到程序里,有兴趣可以去看下它的代码(https://github.com/Irqbalance/irqbalance/blob/master/activate.c),也是把这个文件打开,写对应的数字进去就可以了。
内核-数据处理
最后是数据处理部分了。当数据到达网卡,进入队列内存后,就需要内核从队列内存中将数据拉出来。如果机器的 PPS 达到了十万甚至百万,而 CPU 只处理网络数据的话,那其他基本的业务逻辑也就不用干了,因此不能让数据包的处理独占整个 CPU,而核心点是怎么去做限制。
针对上述问题主要有两方面的限制:整体的限制和单次的限制
while (!list_empty(&sd->poll_list)){
struct napi_struct *n;
int work,weight;
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
goto softnet_break;
整体限制很好理解,就是一个 CPU 对应一个队列。如果 CPU 的数量比队列数量少,那么一个 CPU 可能需要处理多个队列。
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n,weight);
trace_napi_poll(n);
}
WARN_ON_ONCE(work > weight);
budget -= work;
单次限制则是限制一个队列在一轮里处理包的数量。达到限制之后就停下来,等待下一轮的处理。
softnet_break:
sd->time_squeeze++;
_raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
而停下来就是很关键的节点,幸运的是有对应的指标记录,有 time-squeeze 这样中断的计数,拿到这个信息就可以判断出机器的网络处理是否有瓶颈,被迫中断的频率高低。

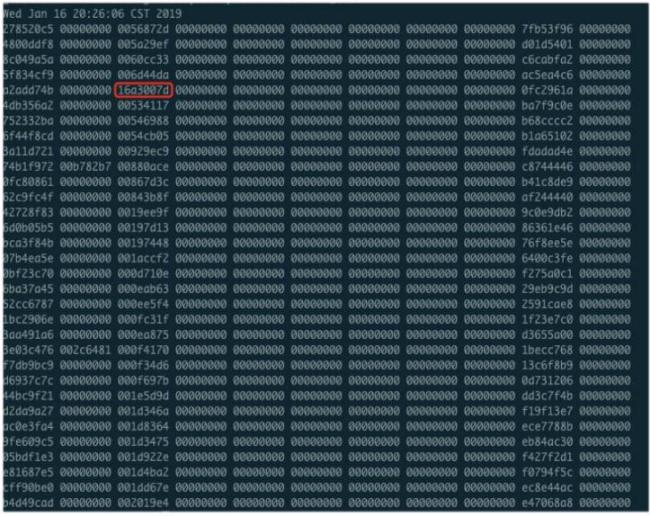
上图是监控 CPU 指标的数据,格式很简单,每行对应一个 CPU,数值之间用空格分割,输出格式为 16 进制。那么每一列数值又代表什么呢?很不幸,这个没有文档,只能通过检查使用的内核版本,然后去看对应的代码。
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,
0, 0, 0, 0, /* was fastroute */
sd->cpu_collision, sd->received_rps, flow_limit_count);
下面说明了文件中每个字段都是怎么来的,实际情况可能会有所不同,因为随着内核版本的迭代,字段的数量以及字段的顺序都有可能发生变化,其中与网络数据处理被中断次数相关的就是 squeeze 字段:
sd->processed 处理的包数量(多网卡 bond 模式可能多于实际的收包数量)
sd->dropped 丢包数量,因为队列满了
sd->time_spueeze 软中断处理 net_rx_action 被迫打断的次数
sd->cpu_collision 发送数据时获取设备锁冲突,比如多个 CPU 同时发送数据
sd->received_rps 当前 CPU 被唤醒的次数(通过处理器间中断)
sd->flow_limit_count 触发 flow limit 的次数
下图是业务中遇到相关问题的案例,最后排查到 CPU 层面。图一是 TOP 命令的输出,显示了每个 CPU 的使用量,其中红框标出的 CPU4 的使用率存在着异常,尤其是倒数第二列的 SI 占用达到了 89%。SI 是 softirq 的缩写,表示 CPU 花在软中断处理上的时间占比,而图中 CPU4 在时间占比上明显过高。图二则是对应图一的输出结果,CPU4 对应的是第五行,其中第三列数值明显高于其他 CPU,表明它在处理网络数据的时被频繁的打断。
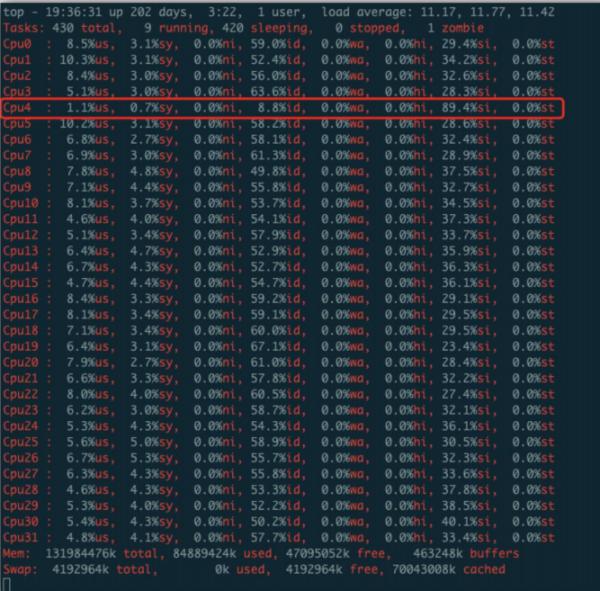
针对上面的问题推断 CPU4 存在一定的性能衰退,也许是质量不过关或其他的原因。为了验证是否是性能衰退,写了一个简单的 python 脚本,一个一直去累加的死循环。每次运行时,把这段脚本绑定到某个 CPU 上,然后观察不同 CPU 耗时的对比。最后对比结果也显示 CPU4 的耗时比其他的 CPU 高了几倍,也验证了之前的推断。之后协调运维更换了 CPU,意向指标也就恢复正常了。
以上所有操作都只是在数据包从网卡到了内核层,还没到常见的协议,只是完成了万里长征第一步,后面还有一系列的步骤,例如数据包的压缩(GRO)、网卡多队列软件(RPS)还有 RFS 在负载均衡的基础上考虑流的特征,就是 IP 端口四元组的特征,最后才是把数据递交到 IP 层,以及到熟悉的 TCP 层。
总的来说,今天的分享都是围绕驱动来做的,我想强调的性能优化的核心点在于指标,不能测量也就很难去改善,要有指标的存在,这样一切的优化才有意义。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板