近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
然而,当我们把目光从 “像不像” 转向 “对不对” 时,一个深刻的问题开始浮出水面:当前视频生成模型虽然擅长制造视觉真实感,却并不真正理解物理世界。
一个球可能在没有接触的情况下突然改变速度;一个下落物体可能无视重力;碰撞、流体、切削、堆积、弹跳等动态过程,经常看起来合理,却经不起基本物理常识的检验。在 VideoPhy-2 这类面向物理常识的视频评测中,即便是表现最好的模型,联合准确率也只有 32.6%。这说明,视频生成距离真正的 “世界模拟器”,仍然存在一条关键鸿沟。
于是,浙江大学、香港理工大学、树根科技与三一集团联合提出的 NEWTON(Neural Agentic World-Aware Tool-Orchestrated Navigation)—— 把 Agent 范式搬进视频生成里:与其继续把物理硬塞进生成器的权重里,不如让一个会规划、会调用物理工具、会自查自纠的 Agent,把生成器 “降级” 成它工具箱里的一件兵器。

视频生成为什么总是 “物理不稳”?
过去我们习惯认为,只要模型足够大、数据足够多,它终将学会真实世界的物理规律。但 NEWTON 指出,问题的根源并不在模型本身 —— 而是输入本身就不足以唯一确定一段物理自洽的视频,再大的模型也补不回输入端缺失的信息。
文本提示词本质上是对物理世界的高度压缩。比如一句 “啤酒被倒进杯子直到装满”,看似已经描述清楚了事件,但实际上省略了大量决定动态过程的参数:容器形状、泡沫生成、液面上升速度等。模型拿到的只是一句自然语言,却被期待生成一个完整、连续、符合物理规律的视频。换句话说,模型是在信息严重不足的前提下,被要求交出一个物理自洽的完整答案。
关键信息一旦缺失,模型就只能在不完整条件下做幻觉式补全:单帧也许漂亮,时间维度上却处处露馅 —— 液面不升高、刀划过木头却没有凹槽、颗粒倒下却不堆积、物体碰撞却毫无反应。
所以,物理可靠的视频生成不能押在一句 prompt 上。它至少要同时满足三件事:信息要够,能补齐影响动态的物理变量;过程要活,能针对不同场景调用不同的物理工具;结果要能查,生成之后能发现问题、回头修正。
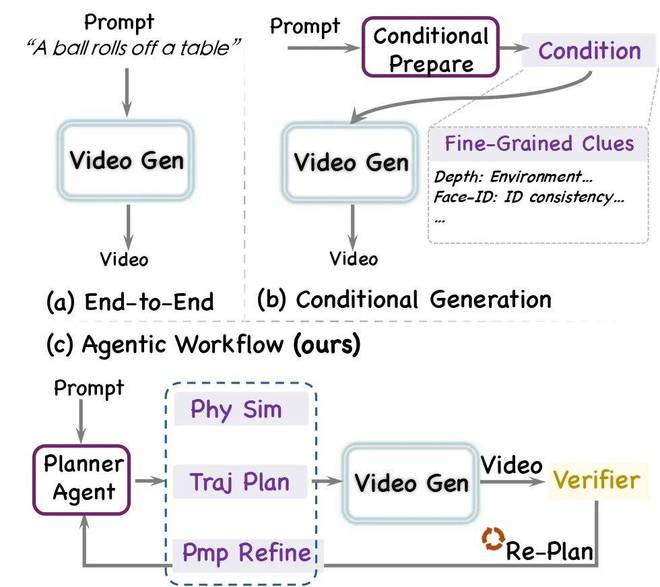
而现有方法往往只能顾上其中一两条。端到端模型把物理知识隐式压进参数,输入端的条件本身就不完整;ControlNet 一类方法依赖预设的单一模态信号,难以随场景切换,缺乏动态性;单轮生成则没有反馈回路,结果不对也无从修起。
NEWTON 的破局思路:把生成变成一个可规划、可验证的过程
NEWTON 的核心变化,是重新定义视频生成系统的工作方式
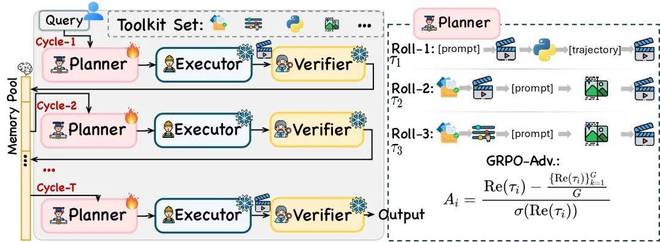
传统范式很短:用户输入 prompt,生成器直接输出视频。这意味着所有物理细节都得由生成器自己一次性猜出来。NEWTON 把这一步改造成了一个多轮 Agent 循环 ——Planner 先分析当前任务缺哪些物理信息、该调哪些工具,Executor 执行工具调用和视频生成,Verifier 给结果打一个物理合理性分数,再把反馈写回下一轮规划。视频生成器在这个循环里不再是唯一主角,只是工具箱里的一个动作;真正负责组织过程的,是可训练的 Planner。
工具库覆盖的是互补的物理维度:
更关键的是,NEWTON不需要改动底层的视频生成模型。无论用的是 LTX-Video 还是 Veo-3.1,生成器始终保持冻结。整套系统里真正需要训练的只有 Planner—— 它通过 Flow-GRPO 在真实的多轮工具调用流程中做 on-policy 优化,逐步学会:什么时候该算物理、什么时候该生成关键帧、什么时候该重写场景描述、什么时候该真正触发视频生成。
这样的设计,使得 "物理能力" 不再被困在某一个生成模型内部,而是被抽出来,变成一种可组合、可检查、可迁移的 Agent 行为。
实验表现:不改生成器,也能显著提升物理一致性


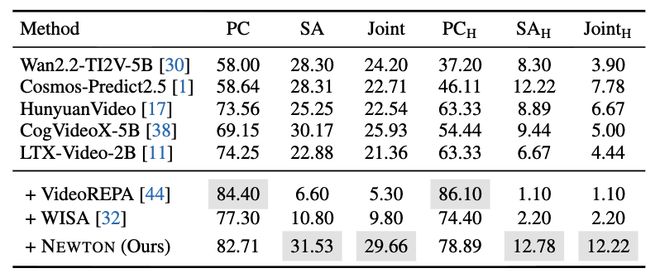
在 VideoPhy-2 基准上,NEWTON 展现出了稳定提升。接入 LTX-Video 后,联合准确率从 21.4% 提升到 29.7%;接入 Veo-3.1 后,在选取的测试集中从 30.7% 提升到 37.4%。这些提升并非来自重训视频生成器,而是来自 Planner 对物理工具、关键帧条件和反馈循环的组织能力。这意味着,即使底层生成器保持不变,只要把 “生成前的物理规格补齐” 和 “生成后的验证修正” 纳入系统流程,视频生成的物理可靠性就能被显著改善。
在具体案例中:倒啤酒时,NEWTON 让杯子随注入逐渐被填满,基线却出现 "杯子早就满了"" 怎么倒都倒不进去 ""泡沫在长液面不动" 这类荒诞画面;刀刻木头时,只有 NEWTON 同时刻出凹槽和木屑;吹泡泡和 LEGO 橄榄球交接的镜头也呈现同样的规律 —— 基线模型常常是 "动作发生了,但世界状态没变",而 NEWTON 能把液面上升、材料移除、颗粒堆积、受力反弹这些有因果的动态完整地呈现出来。
总结
NEWTON 的意义不只在于提升了某个评测指标,更在于它提出了一种视频生成的新范式:未来的视频模型也许不应只是一个端到端的视觉合成器,而应成为 Agent 系统中的一个可调用模块。
当任务涉及真实世界的动态规律时,系统需要的不只是更强的渲染能力,还需要知道缺了什么信息、该调用什么工具、如何验证结果,以及失败后如何重新规划。
从这个角度看,NEWTON 给 “世界模拟器” 提供了一条更务实的路径:不是等待物理规律从黑箱中自然涌现,而是把牛顿请进工具箱,让 Agent 带着物理知识,一步步把视频生成得更真实、更可信。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板