近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
然而,这种 “显式思考” 也带来了一个越来越突出的效率问题:模型往往需要生成大量的中间推理文本,导致推理 token 数显著增加,从而带来更高的推理延迟、显存占用和计算成本。尤其在多模态大模型(MLLMs)中,输入通常包含图像、问题和复杂上下文,模型为了完成推理,往往需要先描述图像内容、总结关键信息、分析视觉线索,再逐步推导最终答案。
这个过程虽然接近人类的 “逐步思考”,但对于大模型推理系统而言,每一个额外生成的 token 都意味着一次额外的自回归解码开销。因此,一个最关键的问题就是:大模型的 “思考” 是否一定要以人类可读的长文本形式显式得生成出来
近期,来自浙江大学、Adobe Research、杜克大学等机构的研究团队提出了一种面向多模态大模型的高效推理框架 ——Heima。该方法将冗长的文本 CoT 压缩为少量抽象的 “thinking tokens”,让模型在隐空间中完成高效推理,在大幅减少生成 token 数量的同时,尽可能保留 CoT 推理带来的能力提升。更进一步,作者还构建了基于纯语言模型(LLMs)的解释器实验,对这些抽象的 “thinking tokens” 进行解码与重构,验证了隐藏空间中确实存在可被还原和分析的推理过程。该论文题为 Efficient Reasoning with Hidden Thinking,已被 ICML 2026 接收。

本文第一作者沈轩现为浙江大学 “百人计划” 研究员,研究方向为高效人工智能,主要聚焦于大模型在 GPU、移动端、FPGA 和 ASIC 等多种硬件平台上的高效部署与推理加速,以及面向 AI 计算的计算机体系结构与系统优化设计。
背景挑战
CoT 推理的核心思想是让模型在回答问题前先生成中间的推理过程。例如,对于一道多模态问题,模型可能会依次生成:1. 对输入问题的总结;2. 对图像内容的描述;3. 对视觉线索和问题之间关系的分析;4. 最终答案。这种方式能够增强模型的可解释性,也能提升模型处理复杂任务的能力。然而,其代价也十分明显:模型需要生成大量额外的文本 token,导致推理成本变高。这些中间的 CoT 文本虽然对人类可读,但其中也存在大量冗余信息。
现有一些方法尝试在文本模型中进行 latent reasoning 或 CoT 压缩,但它们通常局限于小规模语言模型、文本任务或特定数据集。相比之下,多模态大模型需要同时处理视觉输入和语言输入,推理过程也更复杂,因此如何在 MLLM 中压缩 CoT,同时不破坏推理能力,仍然是一个开放问题。论文也指出,已有 latent reasoning 方法在小模型或文本任务上已有探索,但将 CoT 压缩扩展到大规模多模态大模型仍存在明显空白。
核心问题
本文探索的核心问题是:
能否让多模态大模型不再生成冗长的显式 CoT 文本,而是用少量隐式 thinking tokens 来完成推理?
这背后其实有一个很有意思的判断:人类写出来的推理文本,未必是模型内部 “思考” 的唯一形式。对于模型而言,中间推理过程也许可以被压缩为更抽象、更紧凑的隐空间表示。只要这些表示能够保留对最终答案有用的信息,模型就不一定需要完整输出所有的推理文本。因此,Heima 的目标不是简单地 “删除” CoT,而是尝试把原本冗长的 CoT 推理过程压缩进少量特殊 token 中,让模型仍然具备逐步推理能力,但避免在推理时生成大量自然语言中间步骤。这就类似于把 “写满一整页的草稿纸” 压缩成几个模型内部能理解的思考符号:虽然人类可能看不懂这些符号,但模型可以用它们进行推理并给出答案。
方法概览
为了解决上述问题,本文提出了 Heima,一个面向多模态大模型的 CoT 压缩与隐式推理框架。论文摘要中将 Heima 描述为一种有效的 CoT compression framework,能够把长 CoT 压缩成少量抽象的 thinking tokens,同时保留关键推理信息并去除冗余。整体来看,Heima 包含三个关键设计:
1. 用 thinking token 替代冗长 CoT
传统 CoT 方法会让模型显式生成完整的中间推理文本。例如,针对一张汽车图片以及问题 “这辆车属于哪个品牌?有哪些视觉特征可以支持这一判断?”,模型可能会先逐步描述图像内容,再基于视觉线索进行推断:

这张图中有一辆黑色汽车。车头有一个特殊的标志。这个标志对应 BMW。因此答案是 BMW。
而 Heima 不再要求模型完整输出这些文字推理,而是将不同阶段的推理过程压缩为特殊的 thinking tokens,例如:
, 结论:这张图片展示了一辆黑色 BMW M3 在路上驰骋。
这些 token 本身很短,但其 hidden states 中编码了对应阶段的推理信息。也就是说,模型生成的不是完整推理文本,而是更紧凑的隐式思考表示。
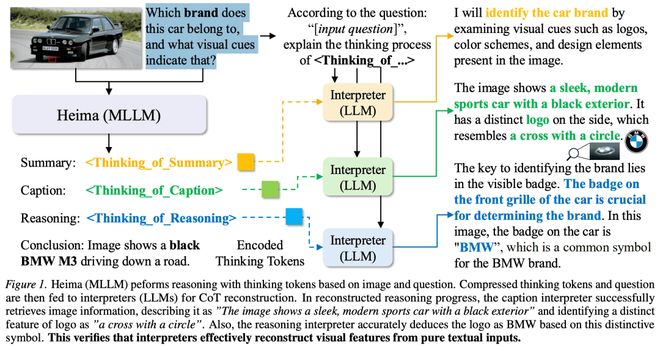
论文图 1 展示了一个汽车品牌识别的示例:Heima 首先基于输入图像和问题生成抽象的 thinking tokens,随后再通过 interpreter 将这些 thinking tokens 重新解码为人类可读的推理过程,例如对汽车外观、车标特征以及品牌归属进行分析。值得注意的是,这里的 interpreter 仅基于传统大语言模型构建,并不直接接收原始图像输入,却仍然能够从纯文本问题与 thinking token 表示中重建出与视觉内容相关的推理信息。这说明 thinking tokens 中确实编码了关键的视觉推理线索,也从实验层面验证了模型隐空间中存在可被解析的推理过程。
2. 渐进式蒸馏:逐步把 CoT 压缩进 token
直接把完整 CoT 一次性压缩成少量 token 是很困难的,因为模型可能会丢失大量推理信息。为此,Heima 采用了progressive distillation的训练策略。具体来说,模型并不是一次性把所有推理阶段都替换成 thinking tokens,而是逐阶段进行压缩。这种渐进式训练可以让模型更平滑地从 “显式文本推理” 过渡到 “隐式抽象 token 推理”,避免一次性压缩带来的性能下降。论文明确提出,Heima 会逐步将每个 CoT stage 蒸馏为 thinking token,而不是一次性完成所有阶段的蒸馏。
3. Interpreter:把隐式思考重新解释成人类可读文本
隐式推理虽然高效,但也带来一个问题:如果 thinking tokens 不是自然语言,人类如何知道模型到底有没有在思考?或者说到底想了什么?
为此,本文设计了adaptive interpreter。它的作用是把 thinking tokens 映射回可变长度的文本序列,从而重建模型的推理过程,并进一步分析压缩引入的信息差距。这一步非常关键,因为它让 Heima 不只是一个 “把推理藏起来” 的加速方法,而是提供了一种分析和验证隐式推理质量的机制。如果 interpreter 能够在没有视觉输入的情况下,从 thinking tokens 中重建出与原始 CoT 接近的推理过程,就说明这些 tokens 确实保留了足够多的推理信息。换句话说,Heima 一方面让模型推理更快,另一方面又通过 interpreter 尽可能保留可解释性。
理论分析
除了方法设计,本文还从信息论角度分析和直觉解释了 CoT 压缩带来的信息差距。核心思想是:将文本 CoT 压缩为 thinking tokens 必然会引入一定的信息损失,但只要这些 tokens 与原始 CoT 之间保留了非平凡互信息,模型的推理能力就仍然可以被保留。


实验结果
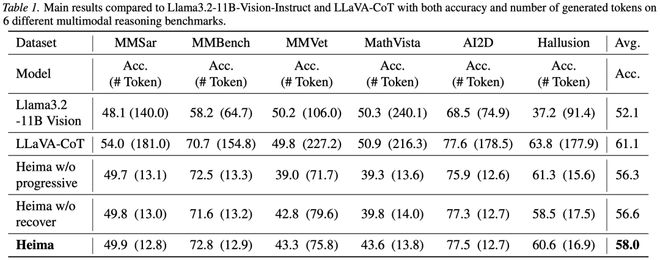
本文在多个多模态推理 benchmark 上验证了 Heima 的效果。Heima 不仅显著减少了推理过程中生成的 token 数量,且在多个 benchmark 上,Heima 能够在大幅减少 token 的同时保留大部分 CoT 推理能力。这意味着 Heima 能够将原本冗长的 CoT 推理压缩到非常短的 thinking token 序列中,从而显著降低自回归解码成本,并且压缩后的 thinking tokens 仍能保留处理视觉幻觉和语言幻觉问题所需的关键信息。
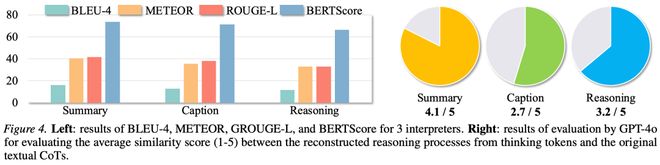
另外,为了进一步验证 thinking tokens 中是否真的保留了推理信息,本文训练了对应的 interpreter,并评估重建文本与原始 CoT 的接近程度。论文结果显示,interpreter 能够从压缩后的 thinking tokens 中重建出连贯的 reasoning progress。尤其在 summary、caption 和 reasoning 三个阶段中,interpreter 都能恢复出一定程度的人类可读推理内容。这说明 Heima 并不是简单地把推理过程 “黑箱化”,而是通过 interpreter 提供了一种观察隐式思考内容的窗口。
总结与展望
Heima 提供了一种新的多模态大模型高效推理思路:与其让模型显式生成冗长的自然语言 CoT,不如将中间推理过程压缩进少量 thinking tokens 中,让模型在隐空间中完成更高效的 “隐藏思考”。相比传统 CoT 方法,Heima 的优势主要体现在三个方面:
从更长远的角度看,Heima 探索了一个非常重要的问题:大模型的推理过程是否必须以人类语言显式展开?如果模型可以用更紧凑的隐空间表示完成复杂推理,那么未来的大模型推理或许可以在 “可解释性” 和 “效率” 之间找到新的平衡点。这一工作不仅为多模态大模型的 CoT 压缩提供了新方法,也为 latent reasoning、efficient reasoning 和 scalable multimodal reasoning systems 提供了新的研究方向。随着多模态模型被部署到更多真实场景中,如何减少推理 token、降低延迟和提升系统吞吐,将成为大模型走向实际应用的重要问题。Heima 的提出,为这一方向提供了一个简洁而有效的解决方案。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板