
新智元报道
编辑:LRST
【新智元导读】语音合成这两年发展迅速:把一段话顺顺当当地念完,已经不算难事;难的是该慢的时候慢,该顿的时候顿,该强调的时候真能把重点托出来。
语音合成这些年最明显的进展,是越来越会模拟真人输出语音。
自然度更高了,声音更像真人了,零样本克隆也越来越成熟了。可一旦要求模型别再只是平着往下读,而是对一句话内部的节奏做有选择的安排,问题就暴露出来了。很多系统能做到整体变快、整体变慢,也能给整段话套一个风格标签,但真到关键位置,往往还是一起变,很难做到只改重点区域。
而产品场景里,用户在意的常常就是只改重点区域。
验证码播报里,数字之间要不要刻意拉开;导航播报里,动作信息要不要被单独顶出来;教学纠音里,两个容易混淆的词能不能被故意说出差别;剧情化表达里,结尾那个关键词之前能不能多留半拍。这些需求都不是靠整句降速就能混过去的。
华南理工最新工作MAGIC-TTS首次把字级时长和边界停连同时拉到 token 级,做成了局部可控的语音生成能力。

论文链接: https://arxiv.org/abs/2604.21164v1
代码链接: https://github.com/yongaifadian1/MAGIC-TTS/tree/main
演示链接: https://yongaifadian1.github.io/MAGIC-TTS/
所以,这篇工作真正值得看的点在于它在把一件以前很难稳定实现的能力往前推:让模型不只是会发声,还开始会安排一句话内部的节奏,同时不牺牲合成质量和克隆语音的相似程度。
如果把MAGIC-TTS放回真实使用场景里看,它最先改动的,其实是三类任务。
第一类,是高辨识播报。
这一类任务的核心不是更自然,而是更不容易听错。论文里拿了验证码播报做例子。作者先给整句内容设置均匀时长,再刻意把中间分组的停顿拉开,最后进一步把数字本身也放慢。这样做的结果不是简单的整句慢下来,而是用户先听清分组,再听清每个数字。换到产品里,这种处理显然不只适用于验证码,还适用于订单号、取件码、地址、药品名这类高辨识内容。
地铁播报也是同一路数。作者没有让整句一起拖慢,而是把站点出现前的停连做得更明显,同时把真正需要乘客注意的站名压得更重一些。对这类高实时任务来说,节奏是否准确,很多时候比声音是否足够像真人更有价值。
第二类,是教学和纠错。
论文里给出的案例是英文近音词纠正。作者通过缩短前一个词、拉长后一个词,并在纠正关系出现前加入短暂停顿,让两者之间的差异不再糊成一团。这个例子最关键的地方,不是能合成英文,而是模型开始能利用节奏本身去帮助区分语义关系。
这类能力一旦成熟,对外语学习、儿童跟读、口语训练会很直接。因为教学场景需要的从来不是一台平铺直叙的朗读器,而是一个能把差异做出来、把重点放出来的示范系统。
第三类,是表达型语音。
论文还展示了一个戏剧化场景:在句尾关键词出现之前先留一小段空白,再把最后那个词拉开。这个动作非常小,但听感会一下从把句子读完变成把情绪送出来。也就是说,局部节奏控制影响的不只是信息清晰度,还会开始影响叙事张力和表现力。
过去,这类处理通常被认为属于真人配音、导演调度或者后期剪辑的领地。现在,TTS 也开始往这个方向摸了。
为什么这件事早就该有
却一直很难真正落地
第一,整句控制和句内控制,根本不是一回事。让一整段话慢一点,本质上还是全局调节;但让某个词多占几十毫秒、让某个边界多留一段停顿,要求的是模型在局部位置精确地重新分配时间。
第二,停顿和字时长也不是同一种难度。停顿更接近边界留白,内容时长则直接涉及 token 内部的声学展开。前者像在内容之间插空,后者则是改内容本身怎么展开。真正难啃的是后者。
第三,局部控制越细,对训练时的监督边界越苛刻。假如在训练中,一个 token 的起止位置本来就不稳,那么后面在推理时不管是要拉长它,还是要在它后面加停顿,都会变成一件漂浮不定的事。
所以,这类问题真正卡住行业的,往往不是有没有想法,而是能不能把它做成一个不会稳定的,可以应用在真实场景的模型。
方法
从方法上看,MAGIC-TTS 真正抓住的,是三个更底层的环节
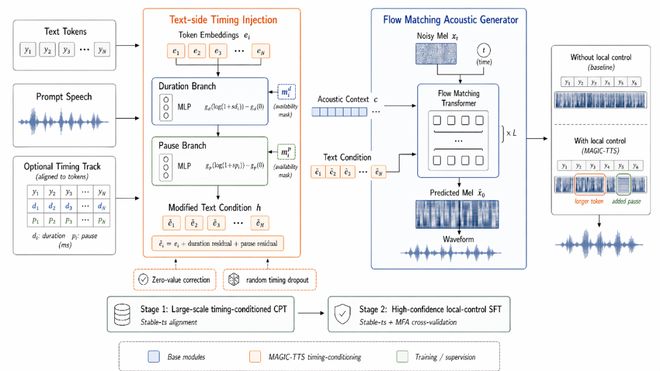
第一,是把一句话里的两种时间因素拆开。
这篇工作没有再把节奏当成一个模糊的整体感觉去学,而是明确地区分每一个词要占多久和每一个词之后要停多久。前者对应 token 本身的展开长度,后者对应边界停顿。把这两件事拆开,等于承认了一句自然语音的节奏,本来就不是一个总时长数字能够概括的。
第二,是先把每个词的边界监督校准。
论文里一个很关键的工程步骤,是先用 Stable-ts 在总时长为3万小时大规模语音上构造 token 级时序标签进行持续预训练,再用 Stable-ts 和 MFA 做交叉验证,筛掉不可靠样本。最终留下来的高置信度子集总时长 230.72 小时,进行精细指令微调。这个步骤决定了后面的控制是不是建在坚实的基础上。如果边界不准,所有精细调节都会被噪声吞掉。
第三,是解决停顿控制会不会污染内容控制。
这篇工作的一个现实问题:模型为每个位置都编码了内容控制残差和停顿残差,但关键是,不是每个位置都应该有停顿,对于自然语音,大多数时候句子内的字都是黏连在一起发声,因此很多位置的停顿残差天然就该是 0。
但是如果模型单纯采用MLP去编码停顿残差,这会导致如果模型将这些不存在的停顿都编码成有偏信号,整句里就会不断积累无意义干扰,最后把更难学的内容时长控制的影响削弱。论文里的零值校正,本质上就是在处理这个问题:该没有影响的时候,就尽量真的没有影响。
与此同时,作者还专门做了缺失控制鲁棒性训练。原因很现实,用户不可能每次都给整句配一套精细时序。如果一个系统只有在满配控制条件下才表现好,那它就更像实验演示,而不是实际能力。把默认合成和局部调节同时保住,才更接近真正可用的方向。
最值得看的证据,不只是会不会停,而是能不能稳稳地控字。
这篇论文的数据结果里,最重要的其实不是停顿,而是内容时长。
在显式给出token级内容时长和停顿条件之后,每个字的内容时长 MAE(平均绝对误差) 从36.88ms 降到了10.56 ms,相关性从0.588提升到0.918。停顿方面,MAE从18.92 ms 降到8.32ms,相关性从0.283提升到0.793。
为什么说内容时长更关键?因为会停一下相对容易理解,也更容易被实现成边界层面的动作;但把这个 token 本身说得更长一点、又不把整句带坏,难度明显更高。也正因为如此,内容时长指标的大幅提升,比单纯的停顿跟随更能说明问题。
应用场景
如果这条路线跑通,最先吃到红利的那几类产品
最先受益的,还是那些听错一个字都麻烦的场景。
高辨识播报会是第一批,包括验证码、订单号、地址、药品名、导航、车载播报。比起声音不拟人,这些地方最怕的是信息没听清。过去很多系统只能靠整句放慢来保底,但那往往会牺牲效率,且对于重点的突出效果不是那么好;如果节奏能局部编排,系统就能把该重点听的地方单独拉出来。
第二批会是教学纠音。儿童跟读、外语学习、示范式朗读,都更需要一个会示范差异的系统,而不是一个把文本顺着念完的系统。谁能把停连、重音、对比关系更清楚地演示出来,谁在这一类产品里就更有优势。
再往后,是表达型语音。数字人、剧情化配音、音频内容生成、故事讲述,这些方向对局部节奏的要求更高,但一旦能力成熟,带来的产品观感提升也会更明显。
小结
MAGIC-TTS的核心价值在于把语音合成从「把话念自然」推进到「能精细安排句内节奏」,如何同时控制 token 级字时长和边界停顿,让现实应用场景中的重点内容被更清楚、更有表现力地说出来,是下一阶段要重视的问题。
参考资料:
https://arxiv.org/abs/2604.21164
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板