
机器之心编辑部
最近,研究人员李博杰在 arXiv 发布论文,提出一个名为「不可压缩知识探针」的评测框架,尝试仅通过黑盒 API 调用,来逆向估算任意 LLM 的参数规模。

该研究的灵感源于一项持续三年的非正式测试。据李博杰介绍,其团队成员长期向各代主流大模型提出同一个冷门问题:「你了解中科大 Hackergame 吗?」(一项 CTF 网络安全竞赛)。

跨越多个版本的观察结果,直观展示了模型对世界知识认知的发展:2024 年 5 月,GPT-4o 对该赛事题目存在明显的「幻觉」与编造;至 2025 年 2 月,Claude 3.7 Sonnet 已能准确列出 2023 年赛季的 19 道题目;而到了 2026 年 4 月,多个前沿模型已能精确回忆起连续多届赛事的具体细节。
受此启发,在 DeepSeek-V4 发布后,研究团队利用 AI Agent 历时四天自主构建了完整的 IKP 正式数据集。该数据集包含 1400 个问题,按信息的稀缺程度划分为 7 个层级,并在涵盖 27 家厂商的 188 个模型上进行了全面测试。
研究的核心假设在于:模型的逻辑推理能力可以通过训练技巧被压缩或蒸馏,但对冷门「事实性知识」的记忆容量则无法大幅压缩,其主要取决于模型的物理参数规模。
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。
根据该方法,论文给出的估算数字(90% 置信区间约为 0.3 至 3 倍)如下:
论文同时指出另外两项发现:
一是引用数量和 h 指数并不能有效预测研究者是否被模型记住,模型更倾向于记住那些产生了领域性影响的工作,而非高产但影响相对分散的学者;
二是跨越三年的 96 个开源模型数据显示,事实记忆容量的时间系数在统计上接近于零,这与此前「Densing Law」所预测的效率随时间提升的规律相悖,研究者据此认为推理能力基准趋于饱和,而事实容量仍主要受制于参数规模。
这组直观的数据迅速在技术社区传播并引发广泛讨论,但也伴随着巨大的争议。
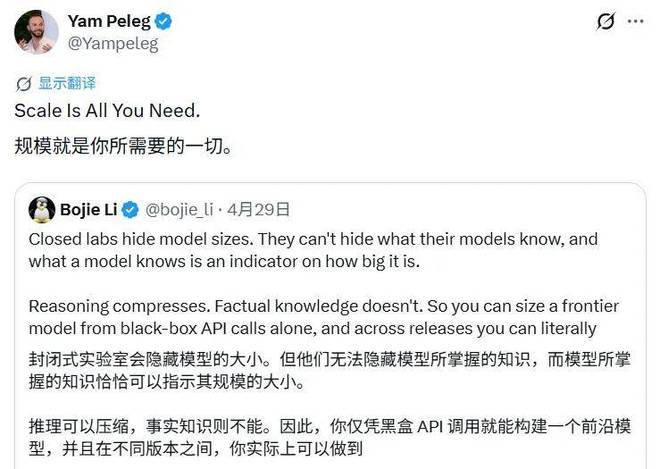
有博主基于这组估算数据,结合近期 Claude Opus 4.7 在部分长文本任务中的主观体验波动,推演出一套完整的逻辑:Anthropic 因算力储备不足(仅为 OpenAI 的四分之一),在训练 Mythos 模型后资源见底,被迫将 Opus 4.7 的参数量从上一代的 5.3T 「反向升级」阉割至 4T;而 OpenAI 则凭借充足的算力将 GPT-5.5 堆到了 9T,从而实现了体验上的反转。
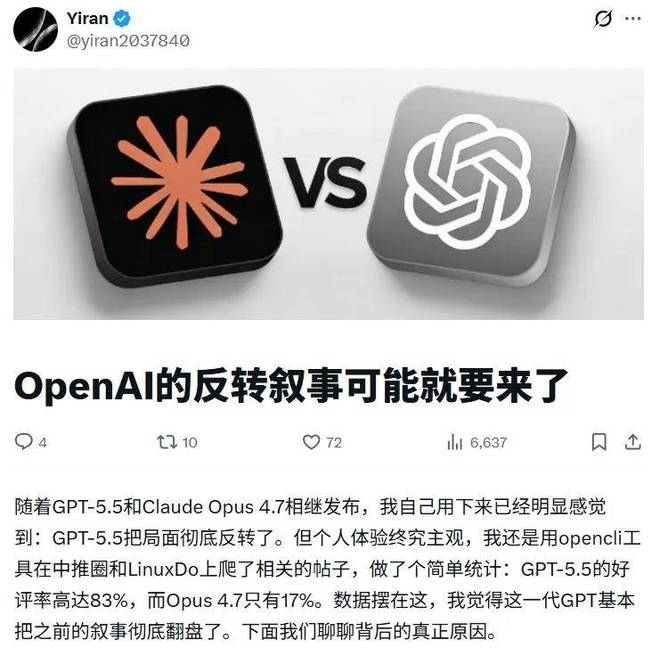
也有多位研究者和从业者对估算数字及方法论提出了不同程度的质疑。
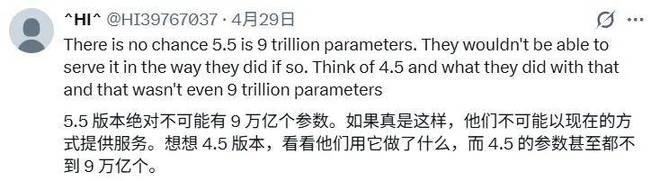
对于 GPT-5.5 约 9 万亿参数的估算,部分用户认为与实际服务能力不符,指出若规模真达到这一量级,OpenAI 现有基础设施难以支撑此前的推出方式,且 GPT-5.4 到 GPT-5.5 的性能提升幅度与 10 倍参数差距并不匹配。有人认为两者规模比约在 2 倍左右更为合理。
同时,定向引入「合成数据」进行微调,同样能显著提升模型对冷门知识的掌握度,这会直接干扰「事实知识不可压缩」的核心前提。

根据该方法估算,Gemini 2.5 Pro 和 Claude Sonnet 的规模约 1.7T,而行业已知国内模型 Kimi k2.6 和 GLM 5.1 约为 800B。若参数差距仅在两倍左右,单纯的数据差异极难解释目前两者间的巨大性能鸿沟。

此外,业内长期流传的 GPT-4 规模约 1.7T,这与论文估算的结果出入极大。

发起讨论的另一位 X 博主也补充说明:「这些数字不应被视为事实,置信区间非常大,我私下收到的反馈表明某些模型的估算可能相差甚远。」

当然,在争议与质疑之外,技术社区中也涌现出了许多极具建设性的正向探讨。
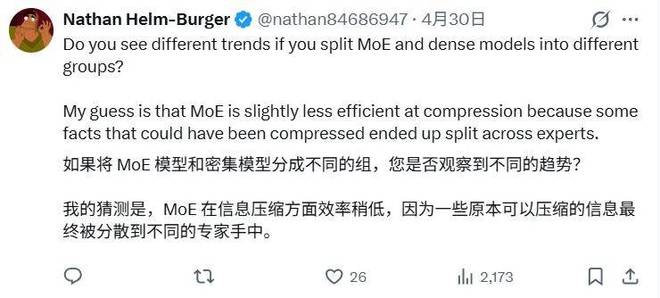
例如,有用户认为 MoE 架构和稠密模型在知识压缩效率上可能存在本质不同(MoE 的事实可能被分散在不同专家中),建议将这两类模型分开统计以观察趋势。

对这组数据你怎么看?
https://x.com/deedydas/status/2049523583517634862
https://x.com/bojie_li/status/2049314403208896521
https://www.zhihu.com/pin/2032769685012361774
https://x.com/yiran2037840/status/2049827667034439821
https://x.com/Yampeleg/status/2049573913399607711
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板