雷科技(ID:leitech)算了下,距离DeepSeek上一次大版本更新已经过去484天,虽然期间一直有小版本更新,也引发了不少讨论,但这终究不是大家期待的V4。

图源:DeepSeek
不过,好消息是我们终于不用再等了,DeepSeek V4在4月24日早上10:56正式发布,首发就有Flash和Pro两个版本。这个消息很快就在海外刷屏,DeepSeek V4发布的推文,短时间内就收获了数万点赞和数百万次浏览,评论区也是挤满了人。
图源:X
DeepSeek V4的关注度实在太高,以至于DeepSeek不得不在官方推文下留言:
请仅以我们官方账号发布的 DeepSeek 新闻为准。其他渠道的声明并不代表我们的观点。
DeepSeek发布这个声明的原因,是此前有人谣传DeepSeek迫于压力将不会开源V4版本(或仅开源小参数版本)。这个谣言甚至在一定程度上引发了开源AI社区的恐慌,不过现在这些谣言都被DeepSeek V4的全模型全量开源击碎了,而且还是大家熟悉的Apache 2.0许可证。
有外国网友直接在底下留言:开源人工智能之王回归了。
图源:X
对的,DeepSeek,回来了。
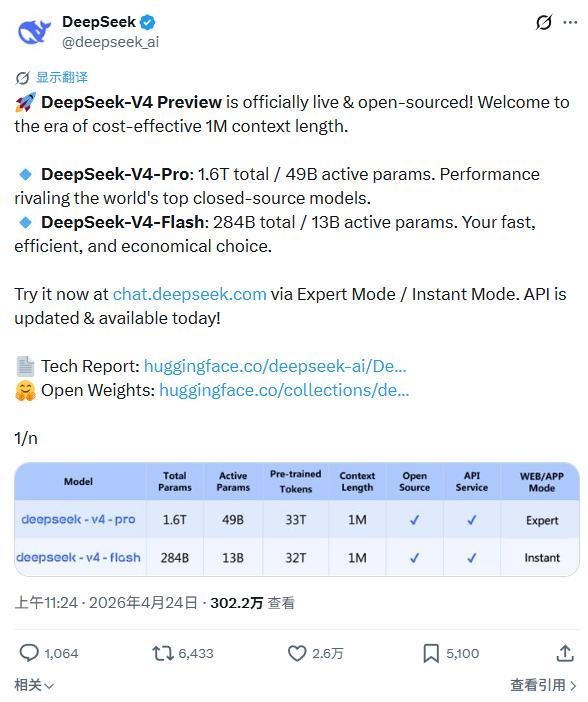
此次发布的DeepSeek V4预览版本分为Pro和Flash两个模型,其中Pro面向复杂推理、高阶Agent和高强度任务,Flash则面向高频调用、低成本部署和快速响应场景。
其中V4-Pro采用1.6T总参数、49B激活参数的MoE架构,V4-Flash则为284B总参数、13B激活参数,两者都支持100万 token 的上下文长度。虽然参数差距巨大,但是根据官方的说法,他们借助算法优化了两个模型的参数调用,使得两个模型在日常任务中的表现几乎相同。

图源:DeepSeek
在小雷看来,这也揭示了DeepSeek对下一阶段大模型竞争方向的判断:模型不只是要更强,还要更便宜、更开放,这样才能更容易被企业和开发者真正用起来。如果你深度使用过OpenClaw,云端Token的消耗速度肯定会让你印象深刻,随着AI的用途越发广泛、能力越发强大,Token成本已经成为所有人都必须面对的问题。
但是,很多任务其实并不需要Pro级的AI模型去处理,比如办公辅助、内容摘要、数据整理等场景,更需要的是速度、稳定性和成本控制。所以将模型一分为二,然后让Flash版在轻量化任务中保持Pro的性能,就足以让使用者和企业节省大量的Token费用。
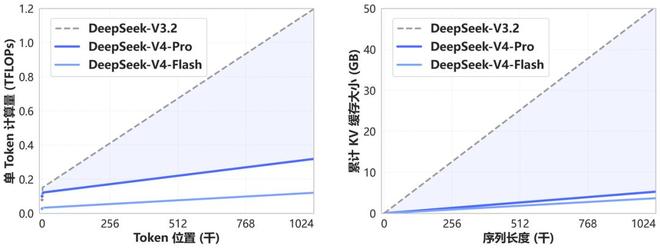
聊回DeepSeek V4,小雷觉得最值得关注的就是百万级 token 上下文。对普通用户来说,这意味着更长的文档、更复杂的对话、更完整的项目资料,可以被一次性纳入模型处理,不用再拆分成多个片段分阶段完成。
图源:DeepSeek
而且DeepSeek V4的Agent及推理能力也得到了大幅度增强,配合更长的上下文,足以让其具备出色的连贯操作能力,这也是为未来的“Claw”生态大爆发提前做好准备。小雷认为,DeepSeek赶在如今的时间段发布V4版本,肯定也是有这方面的考量。
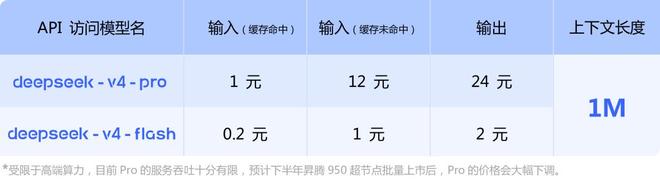
更关键的是,DeepSeek V4延续了DeepSeek一贯的高性价比路线。过去很多大模型竞争喜欢强调参数规模和榜单成绩,但DeepSeek却更强调工程效率和使用门槛,因为它真正想解决的不是让少数人看到技术上限,而是让更多人承担得起AI成本。
图源:DeepSeek
这种思路对国产AI非常关键,中国市场有庞大的中小企业、垂直行业和内容生产需求,但它们不可能长期承受高昂的海外模型调用成本。DeepSeek V4如果能在性能和价格之间继续保持平衡,就会成为更广泛应用场景里的基础模型。
更何况单论开源模型的话,在目前的各项测试中DeepSeek V4都几乎拿到了第一,并且媲美海外闭源模型的最新版本(不过V4测试时GPT 5.5和Opus 4.7都还没发布)。开源意味着你只需要投入前期的硬件成本,就能够近乎零成本使用该模型,这对于不少大型企业来说也极具诱惑力。
既然聊到硬件成本,那么就不得不提DeepSeek V4对国产算力卡的支持了。在V4版本的开发过程中,华为、寒武纪等中国芯片企业都深度参与其中,并且与DeepSeek一起基于国产芯片重构AI大模型的算法逻辑并进行生态适配。
其实,在过去很长一段时间里,国产AI芯片面临的最大问题,并不是没有产品,而是缺少足够强、足够主流的真实业务负载,去测试国产算力芯片是否真正能够稳定运行主流大模型。
当然,你要拿Qwen、kimi、豆包等AI模型去跑也确实可行,但是因为模型都是基于CUDA生态研发的,想在昇腾等芯片上跑通就需要借助兼容层来运行,相当于牺牲效率来换取低廉的硬件成本(某种程度上来说也是不得已而为之),也很难展示国产芯片的真正性能。
而DeepSeek V4的出现就解决了这个问题,它既有长上下文需求,又有复杂推理需求,还会被大量开发者和企业调用。如果国产芯片能在这样的模型上跑出稳定表现,肯定会比单纯公布硬件规格更有说服力,同时也能证明基于国产芯片深度适配后的国产模型,在性能和性价比上依然能够跻身全球前列。

图源:雷科技
对华为昇腾来说,DeepSeek V4应该是今年最重磅的项目了。虽然昇腾过去已经在政企、运营商、云计算和AI训练推理场景里积累了不少案例,但要真正形成生态,还需要更多头部模型和开发框架的支持。
除了华为昇腾,还有另一个值得注意的企业——寒武纪,作为另一家在首日就宣布支持DeepSeek V4的芯片企业,它也受到了很多关注,只有少数在开发阶段就已经开始进行优化的芯片,能够在首日直接适配DeepSeek,适配的国产AI芯片数量超过了英伟达芯片。虽然早前传闻DeepSeek会放弃对CUDA生态的支持,但现在看来显然是误传。
事实上,DeepSeek的早期版本仍然是在英伟达的硬件上训练出来的,后续才逐渐转向华为昇腾,并且首批硬件访问权限仅提供给华为,等于是拉着华为一起搞“联合研发”。

图源:雷科技
这种做法的效果是显著的,基于昇腾950超节点,DeepSeek V4-Pro在8K输入场景下可实现约20ms的单token解码时延,单卡Decode吞吐约4700 TPS,V4-Flash则可实现约10ms的时延,单卡Decode吞吐约1600 TPS,是英伟达此前可公开出口给中国的H20算力卡的2.87倍。
这些数字的意义,不是说让国产芯片的海报上又增添几串数字,而是让市场第一次可以用更接近真实应用的方式去评估国产AI算力。而且也告诉市场,大模型推理不是简单看芯片峰值算力,还要看显存访问、并行调度、低精度计算、通信效率和推理框架的协同。
虽然英伟达的算力卡性能确实称得上全球最强,但是其真正的核心是CUDA生态,所以国产芯片想要追赶英伟达,就不能只靠堆硬件参数(制程限制下一时半会儿也追不上),而是要让模型、框架和应用一起迁移过去,打造真正的软硬件协同。
可以说,DeepSeek V4给Qwen、豆包、kimi等国产顶级大模型提前蹚了路,告诉大家:国产芯片是真的行。
在写这篇文章查询资料的时候,小雷还看到了一则新闻:英特尔财报发布,Q1营收超预期,盘前股价飙升近30%。在英特尔的财报中,最值得关注的就是数据中心与人工智能业务部门(DCAI)营收达51亿美元,同比增长22%。
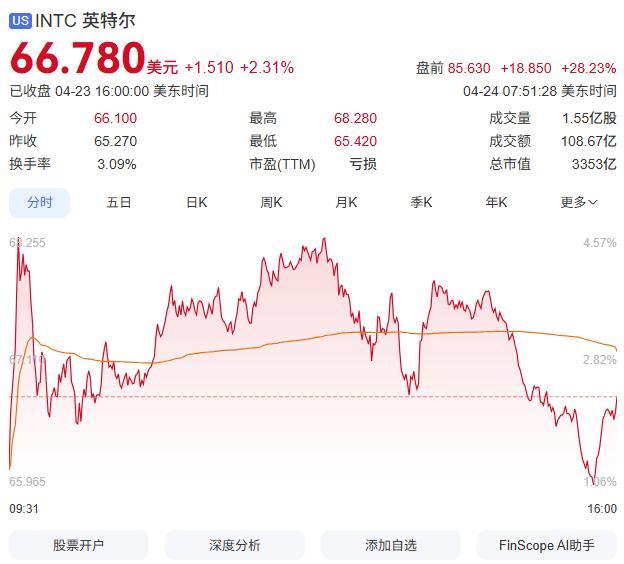
图源:百度股票
AI的需求,正在从GPU逐渐转移到CPU上。有读者可能好奇,小雷为什么要在DeepSeek的文章里提这个?因为DeepSeek恰恰是CPU需求增长的主要推手之一,其V4版本就引入了年初曝光的mHC架构,该架构的核心逻辑是“查算分离”。
举个例子,以前的AI大模型,查资料和推算都是在GPU上完成的,不仅挤占算力,也占用大量显存;而mHC架构则是将模型中静态数据(即非调用数据)存储在CPU的系统内存中,GPU仅需处理推理所需的数据即可。
这种设计,直接将大参数模型对显存的压力转移到了CPU的系统内存上,而CPU即使是消费级的产品,也可以轻松挂载128GB乃至256GB的内存。这使得万亿参数规模的DeepSeek V4无需堆叠昂贵的显卡阵列就可以完成本地化部署。
不过,CPU也因此需要更深度地介入到AI模型推理中,这使得高性能、高能效且高内存带宽支持的处理器更受欢迎。而英特尔此前发布的至强6最高可支持12通道内存,单内存规格最高为256GB,意味着一颗CPU最高可挂载3TB的系统内存(在英特尔的产品线中,甚至有支持4TB的特化版本)。
某种程度上,mHC架构也算是降低了市场对HBM内存(VRAM)的需求,却让压力回到了DRAM上。短期来看,可能确实让内存的价格稍微回落(毕竟DRAM的制造难度比HBM小很多),但是长期来看,估计会让所有内存都处于持续的紧缺状态,消费电子行业接下来可能还要继续承压。

图源:veer
而且,随着类“OpenClaw”应用的普及,PC对CPU的要求也更高,因为AI需要一个高效的CPU在端侧进行指令处理和执行。这也使得英特尔的新处理器备受关注,酷睿Ultra 300系列的高能效+高端侧算力设计,恰好满足此类应用的需求。
在开源模型+开源AI应用的双重推动下,英特尔的营收估计还会持续上涨,这也让雷科技(ID:leitech)意识到,如今的AI浪潮中,如何最大程度地利用现有的计算硬件生态,将会是未来AI生态需要优先考虑的事情。
在雷科技(ID:leitech)看来,DeepSeek V4的意义其实已经不只是“又一个强大的国产大模型发布”这么简单,而是告诉我们,模型能力固然重要,但模型能不能被更多人用起来,能不能跑在更便宜、更容易获得的硬件上,才是下一阶段AI竞争的关键。
这不禁让我想到了当年macOS与Windows的竞争,同为最早的图形界面操作系统,前者虽然性能更强,但是因为仅支持苹果的硬件,导致其在后续的几十年里份额仅有Windows的十分之一甚至更低。而在AI领域也是如此,闭源AI模型虽然能力强大,但是普通开发者和小型企业却面临用不起、难以部署等问题。
而DeepSeek V4其实恰好解决了这些问题。首先开源就意味着免费,其次100万 token 上下文和更强的 Agent 能力,又让其真正成为生产力工具,而对国产芯片生态的支持,也让其能够适应不同的硬件环境,相当于给全球的AI开发者们开辟了一条新的康庄大道。
只能说,484天的等待没有白费,DeepSeek这次带回来的,不只是一个更强的V4,而是一个更开放、更低成本、更接近普通人的AI世界。
2026第十九届北京国际汽车展览会将于4月24日至5月3日在北京中国国际展览中心(顺义馆)和首都国际会展中心(新国展二期)举行,本届车展以“领时代·智未来”为主题,集中展现汽车工业的更多黑科技。
比亚迪、小米、鸿蒙智行(问界等)、小鹏、蔚来、岚图等头部品牌集结,多款重磅新车首秀;地平线、Momenta、卓驭等供应商集体秀肌肉,AI大模型深度赋能,高阶智驾、动力电池、超快充技术等前沿科技集中亮相,看点拉满!
雷科技旗下「电车通」将派出报道团直击现场,以“关注电动车,更懂智能化”的专业视角,带来一线独家报道,敬请关注!

 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板