图片来源:unsplash
ChatGPT迎来三周岁生日之际,竞争对手DeepSeek送来了一份“生日礼”,似乎并不想让这位大模型领域的先行者过得那么轻松。
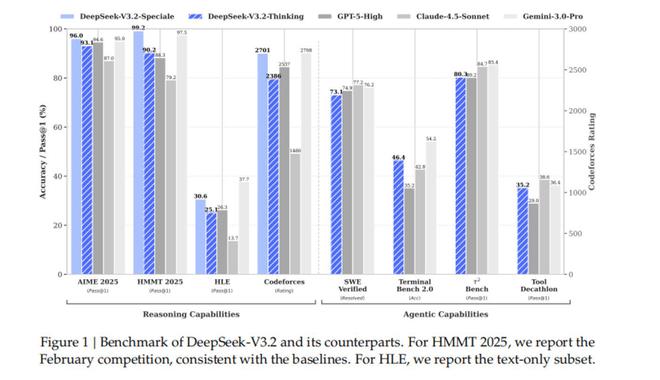
12月1日晚间,DeepSeek一口气发布了DeepSeek-V3.2和DeepSeek-V3.2-Speciale两个正式版模型,同步发布的技术论文显示,这两个推理能力达到了全球领先水平。
根据DeepSeek介绍,已经在网页端、App、API全部更新的“常规军”V3.2重在平衡推理能力与输出长度,适合日常使用。
在Benchmark推理测试中,V3.2与GPT5、Claude 4.5在不同领域各有高低,只有Gemini 3 Pro对比前三者均有较明显优势。
图片来自DeepSeek官微
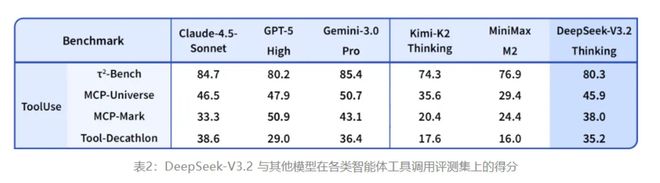
与此同时,DeepSeek方面还表示,对比国产大模型厂商月之暗面新近发布的Kimi-K2-Thinking,V3.2的输出长度大幅降低,显著减少了计算开销与用户等待时间。在智能体评测中,V3.2得分也高于同为开源的Kimi-K2-Thinking和MiniMax M2,是目前的“最强开源大模型”,相比闭源大模型的巅峰也已无限迫近。
图片来自DeepSeek官微
更值得注意的是,V3.2在一些问答场景和通用Agent任务中的表现。在一个关于旅游攻略的具体场景咨询中,V3.2通过深度思考和网站爬虫、搜索引擎等工具调用,给出了十分详尽、精确的攻略和建议。V3.2更新的API首次支持了在思考模式下使用工具调用能力,大大提升了用户获取到的答案的丰富度和适用性。
而且,DeepSeek方面特别强调,V3.2“并没有针对这些测试集的工具进行特殊训练”。
我们注意到,在大模型测试得分越来越高,但在与普通用户的互动中却经常犯一些常识性错误的当下(尤其以GPT5发布时遭遇的吐槽为代表),DeepSeek近期“上新”时经常强调这一点,证明自身走的不是一条只用正确的答案作为奖励机制,打造出了看似高智商的“最强大脑”,却无法胜任用户个人所需的简单任务、简单问题的“低情商”智能体。
而只有从根本上克服这一点,成为所谓高智商、高情商的“双高”大模型,才有孕育出全能、可靠、高效的AI Agent的能力。DeepSeek方面也表示,相信V3.2在真实应用场景中能够展现出较强的泛化性。
为了在计算效率、强大推理能力与智能体性能之间取得平衡,DeepSeek在训练、整合以及应用层面进行了全方位的优化。根据技术论文,V3.2引入了DSA(DeepSeek稀疏注意力机制),能在长上下文场景中显著降低计算复杂度,同时保持模型性能。
同时,为了将推理能力整合到工具使用场景中,DeepSeek开发了新的合成流程,能够系统性地大规模生成训练数据。这一方法促进了可扩展的智能体训练后优化,显著提升了复杂、交互式环境中的泛化能力和对指令跟随能力。
另外,如上文所述,V3.2也是DeepSeek推出的首个将思考融入工具使用的模型,大幅提高了模型的泛化能力。
相比于重视平衡性,专注于如何“说人话、干人事”的V3.2,长思考“特种部队”V3.2 Speciale的定位则是将将开源模型的推理能力推向极致,探索模型能力的边界。
值得一提的是,V3.2 Speciale的一大亮点是结合了上周刚刚发布的最强数学大模型DeepSeek-Math-V2的定理证明能力。
我们此前的文章中提到,Math-V2不仅在2025国际数学奥林匹克竞赛和2024中国数学奥林匹克上都取得了金牌级成绩,在IMO-Proof Bench基准测试评估中还得到了比Gemini 3更好的成绩。
而且,与此前提到的思路类似,这款数学模型同样在努力克服正确答案奖励机制和“做题家”的身份,以自验证的方式突破目前AI在深度推理方面的局限,让大模型真的弄懂何为数学,怎样推导过程,以此形成更强大、稳定、实用也泛用的定理证明能力。
在推理能力上大幅增强的V3.2 Speciale,也在主流推理基准测试中取得了媲美Gemini 3.0 Pro的成绩。不过,V3.2 Speciale的能力优势需消耗大量Tokens,显著升高的成本让其目前不支持工具调用和日常对话、写作,仅供研究使用。
从OCR到Math-V2,再到V3.2和V3.2 Speciale,DeepSeek近期的新品发布不仅每次都收获赞誉一片,也在绝对能力提升的同时不断明确着“实用性”“泛化能力”等发展主线。
2025年后半程,GPT-5、Gemini 3、Claude Opus 4.5相继发布,测试成绩一次好过一次,再加上快速追赶的DeepSeek,“最牛大模型”的赛道已经有些拥挤。而头部的大模型在训练上已有较明显的区别,表现上也各有特色,相信2026年的大模型的竞赛会更加精彩。(作者|胡珈萌,编辑|李程程)
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板