
新智元报道
编辑:好困 定慧
【新智元导读】DeepSeek最新模型V3.2-Exp发布,推出全新注意力机制DeepSeek Sparse Attention(DSA),训练推理提效的同时,API同步降价达50%以上!
刚刚,DeepSeek最新模型上线!
代号DeepSeek-V3.2-Exp,被DeepSeek誉为最新的实验性模型!

这次V3.2主要基于DeepSeek-V3.1-Terminus,并且首次引入「DeepSeek稀疏注意力」(DeepSeek Sparse Attention,DSA),在长上下文上实现更快、更高效的训练与推理。
值得注意的是,这是第一个用「DeepSeek」品牌命名的关键技术(注意力机制)!
我们注意到,DSA正是此前与北大合作、梁文锋署名的那篇中,原生稀疏注意力(Native Sparse Attention,NSA)的改进。


技术报告里的引用
全新注意力机制
DeepSeek-V3.2-Exp的核心武器「DeepSeek稀疏注意力」,首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。

论文地址:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
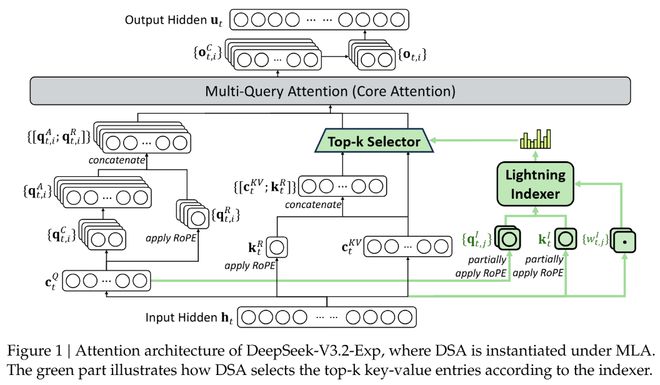
与之前模型最大的不同是,DSA不再让每个Token关注序列中的所有其他Token,而是引入了一个名为「闪电索引器」(lightning indexer)的高效组件。
这个索引器能以极快的速度判断,对于当前正在处理的Token,序列中哪些历史Token是最重要的。
随后,模型只从这些最重要的Token中选取(Top-k)一小部分(例如2048个)进行精细计算。
如此一来,核心注意力的计算复杂度就从O(L²)骤降至O(Lk),其中k是一个远小于L的固定值。
这在处理长文本时,无疑带来了巨大的效率提升。
更关键的是,这种效率提升并非以牺牲性能为代价。
在DeepSeek-V3.1的基础上,团队先用一个简短的「密集预热」阶段来初始化闪电索引器,让它学会模仿原有模型的注意力分布。
随后进入「稀疏训练」阶段,让整个模型适应新的稀疏模式。
最后,再沿用与前代模型完全相同的后训练流程,包括专家蒸馏和混合强化学习(GRPO)。
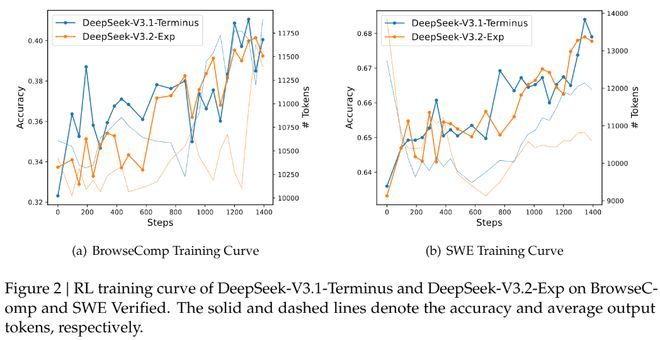
为了严谨地评估引入稀疏注意力带来的影响,DeepSeek特意把DeepSeek-V3.2-Exp的训练设置与V3.1-Terminus进行了严格的对齐。
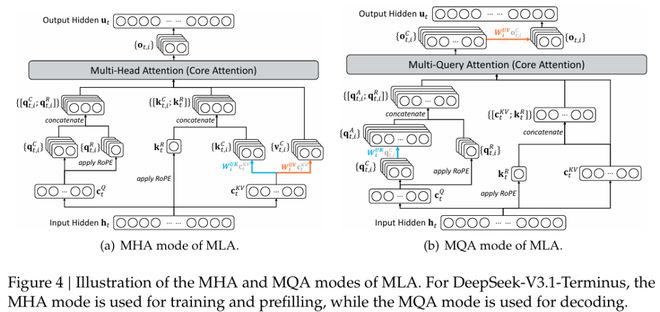
DeepSeek-V3.2-Exp的架构图,其中DSA在MLA下实例化。
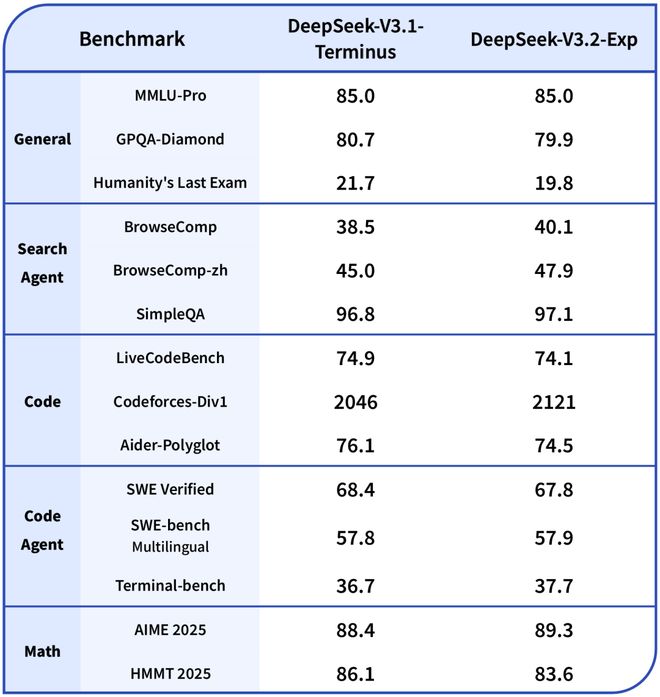
评估结果显示,无论是在短文本还是长文本任务上,DeepSeek-V3.2-Exp的性能与它的「密集注意力」前身V3.1-Terminus相比,都没有出现实质性的性能下降。
与此同时,在实际部署的推理成本测试中,其端到端的加速效果和成本节约非常显著。
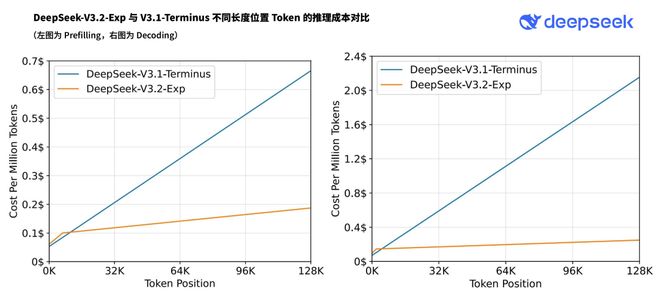
虽然DeepSeek-V3.2-Exp目前还是一款实验性模型,但它所展示的「性能不降、成本骤减」的特性,为大模型突破长文本瓶颈,指明了一条充满希望的工程路径。
价格更便宜
DeepSeek再一次把模型价格打了下来!
得益于新模型服务成本的大幅降低,官方API价格也相应下调,新价格即刻生效。
在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。
目前API的模型版本为DeepSeek-V3.2-Exp,访问方式保持不变。

最后,不得不说,这次DeepSeek太仁慈了,「发布节奏」真的听取了网友的建议,给众多AI界的朋友们放个好假!
参考资料:
https://api-docs.deepseek.com/zh-cn/news/news250929
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板