
新智元报道
编辑:艾伦
【新智元导读】谷歌DeepMind研究团队一年前的研究成果直到昨晚才姗姗揭秘,提出了一种叫做GDR的新方法,颠覆了传统训练中设法剔除脏数据的思路,将饱含恶意内容的数据「变废为宝」,处理后的数据集用于训练,甚至比直接剔除脏数据训练出的模型效果还好,「出淤泥而不染」,「择善而从」。
数据是AI的粮食,「一顿不吃饿得慌」,数据供给充足,模型才能全力以赴。
我们如今用着的强大模型,背后使用了互联网上的海量数据用于训练。
随着硬件与成本的限制,研究者逐渐意识到:光靠堆数据已经难以为继,能否更好地利用数据,才是决定未来性能的关键。
然而,有三个棘手的问题一直难以解决:
第一,公网上可供使用的数据正在逐渐枯竭,预计十年内就会用完。
第二,大量用户生成的内容虽然存在,但含有隐私信息、攻击性语言或版权内容,无法直接使用。
第三,合成数据生成虽是出路,但往往存在多样性不足、与真实数据差距大等问题。
为了解决这些问题,谷歌DeepMind研究团队于昨日公开发表了一篇研究论文:《Generative Data Refinement: Just Ask for Better Data》。

论文地址:https://arxiv.org/pdf/2509.08653
这篇论文的第一作者是华人Minqi Jiang,今年也从DeepMind跳槽去了最近处于风口浪尖的Meta Superintelligence Labs。
回到论文。这篇论文提出了一种新方法:生成式数据精炼(Generative Data Refinement, GDR)。
它的核心思路是——不直接生成全新的数据,而是利用大模型把原始数据「净化」、改写的同时保留有用信息,去掉隐私或有害部分。
换句话说,GDR就像一个「数据清洗器」,既能让脏数据变干净,又能保持原本的知识价值。
GDR的基本思路
传统的合成数据生成依赖大模型反复采样,但容易产生同质化输出,多样性不足。
而GDR采取了颠覆传统思路的方法:
输入部分使用真实世界数据(例如代码、对话、网页内容),处理部分使用大模型作为生成器,按预设规则改写(比如去掉隐私、降低毒性),最终输出一个精炼数据集,既安全又保持原始多样性。
论文中较为详细地介绍了GDR的具体工作流程:
第一步,输入数据:
包括原始文本、代码、对话或网页数据。
数据中可能含有PII、毒性语言、或其他不可用于训练的内容。
第二步,Prompt构造:
给大模型设计一个Prompt,告诉它要做什么:
如果是匿名化任务:提示要求「识别并替换掉敏感信息,用安全占位符替代」;
如果是去毒化任务:提示要求「删除冒犯性表达,但保留事实性内容」。
提示可以是零样本,也可以加入示例,甚至通过微调来增强模型能力。
第三步,生成改写:
模型根据提示,对每个输入样本生成一个新的版本。输出的目标是安全、合理、保留上下文信息。
第四步,验证与筛选:
对生成结果运行验证(例如再跑一次PII检测、或用毒性分类器评估),过滤掉不合格的结果,确保数据集安全。
最后一步,得到精炼数据集D′,可作为训练数据反复使用。
数据多样性依然保持住了,甚至优于直接合成数据。
这种方法有三大优势:
继承真实数据的多样性,因为每条合成数据都「锚定」在一个真实样本上。
避免模式坍缩,不像单纯的合成数据那样,容易收敛到几种套路化表达。
适配不同任务,只需换提示词或微调,就能针对匿名化、去毒化等不同场景。
当然,GDR的代价是需要额外的计算。最坏情况下,相当于再训练1/3次模型。
但一旦得到干净数据,它可以反复使用,长期来看非常划算。
为了验证GDR的效果,文章进行了三个不同角度的实验。
实验一:代码匿名化
代码库中常常藏着敏感信息,例如邮箱、密码、API Token、私有URL。
这些信息如果进入训练数据,不仅存在泄露风险,还可能导致模型在输出时「背诵」隐私。
传统做法是DIRS服务:只要检测到可能的PII,就直接丢弃整个文件。但这种「宁可错杀」的方式,可能导致数百万行有价值的代码被浪费。
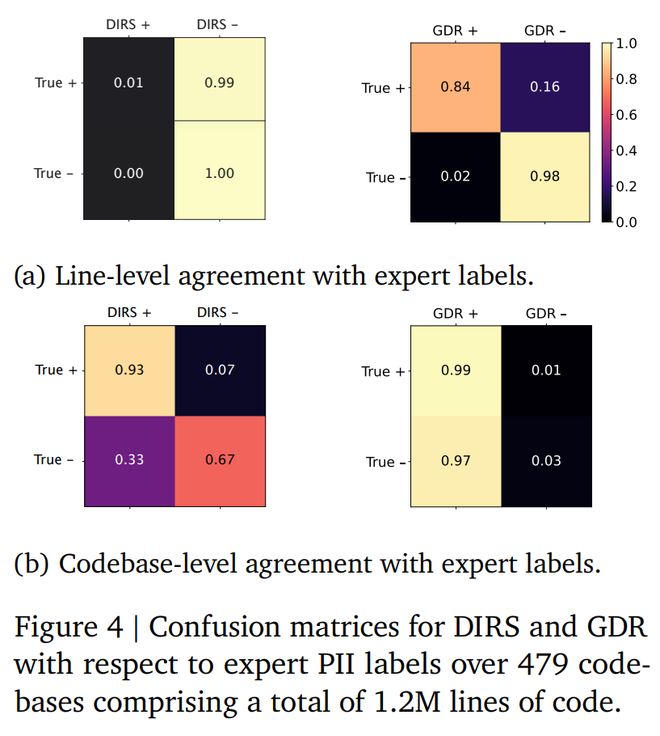
研究者在120万行、479个开源库上对比了GDR与DIRS:
行级别标注结果表明:GDR能更精准地找到PII,并用占位符替换;
DIRS误判率高,大量无害数据被误删;
GDR虽然有少量误报(比如把安全的变量名也替换掉),但这些大多可以通过静态分析检测并修复。
实验结果表明,GDR在保持数据可用性方面,远优于DIRS服务这类传统方法,是大规模代码匿名化的可行方案。
实验二:对话去毒化
如仇恨言论、性别歧视和恶俗等有害内容,在网络上比比皆是。
直接训练这样的数据可能让模型学会错误的价值观,甚至输出危险内容。
研究团队选择了臭名昭著的4chan /pol/讨论区(某种程度上类似国内孙笑川吧的一个充满恶意内容的互联网社区)数据集,抽取了10万个对话对(pol100k),然后用Gemini Pro 1.5零样本提示进行GDR去毒化。
PerspectiveAPI毒性评分:pol100k为0.19,GDR精炼后降到0.13,甚至低于同模型生成的SyntheticChat(0.14)。

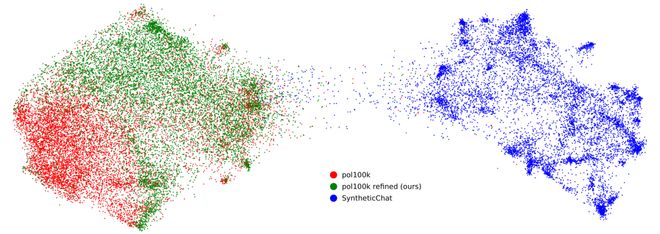
UMAP可视化显示,精炼数据的分布依旧接近真实数据,而纯合成数据出现了明显的模式坍缩。
研究者让模型在去毒化数据上微调后,发现它仍然能保留世界知识,并且生成风格更接近人类。检测系统甚至有31%的概率分不清它和人类对话。

实验结果表明,GDR清洗有害数据的同时,也保留了其中包含的知识,「出淤泥而不染」,「择善而从」。
实验三:多样性对比
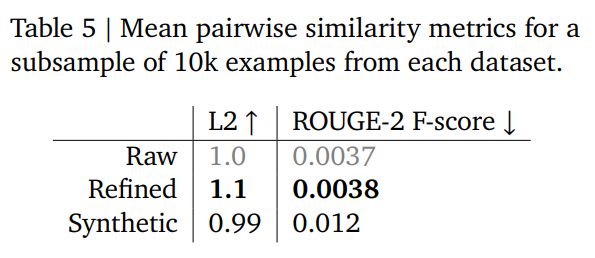
研究者使用了ROUGE-2和嵌入余弦距离指标比较pol100k、精炼版和SyntheticChat。
GDR精炼后的数据,多样性不仅比SyntheticChat高,还略微超过了原始数据。
实验结果表明,GDR不仅起到了安全过滤的作用,还顺带增强了数据的多样性,一举多得。
GDR:变废为宝的「点金术」
GDR就像数据世界的「净水器」,把杂质过滤掉,却让养分完整保留。
它把原本的脏数据变成「可用燃料」,为大模型的发展输送源源不断的清洁能量。
它是AI时代能变废为宝的「点金手」。

迈达斯之手
在数据枯竭与隐私风险的双重挑战下,GDR提供了一条出路。
未来的大模型的持续进化,离不开这些人类的巧思与苦功。
参考资料:
https://arxiv.org/abs/2509.08653
https://x.com/MinqiJiang/status/1967685550422598067
https://www.linkedin.com/in/minqi-jiang-585a6536
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板