无需海量数据标注,智能体也能精确识别定位目标元素了!
来自浙大等机构的研究人员提出GUI-RCPO——一种自我监督的强化学习方法,可以让模型在没有标注的数据上自主提升GUI grounding(图形界面定位)能力。

何谓GUI grounding?为什么要提升这项能力?
简单而言,近年来,以视觉-语言模型为骨架的GUI智能体正在迅猛发展,只需要一句语言指令,它们就能像人一样手眼协同地操作电脑、手机、网页等界面。
GUI智能体的一个关键能力在于GUI grounding,也就是根据用户给出的自然语言指令,GUI智能体需要在用户界面中精确地识别并定位可操作的目标元素。
良好的GUI grounding能力可以使得GUI智能体更好地理解图形界面,以及完成更加精准地界面交互。
然而,想要训练这样一种看似简单的能力,却需要大规模高质量的标注数据——当前绝大多数方法动辄需要上百万级的标注数据,而构建这样的高质量的标注数据需要大量的人工和时间成本。
而GUI-RCPO正好解决了上述问题,其核心原理如下:
通过创新性地将Test-time Reinforcement Learning的思想迁移到GUI grounding任务上,利用模型在多次采样之间呈现出来的区域一致性来引导模型在无标签的数据上进行自我提升。
具体内容如下——
GUI-RC:模型采样“求同存异”
当模型针对同一指令进行多次预测时,由于坐标空间的连续性和解码策略带来的随机性,模型会产生不同的预测区域。
尽管这些预测区域的范围可能互不相同,但是它们会存在一定的空间重叠,这种空间重叠实际上蕴含了一种隐式的置信度信号,重叠程度越高潜在地说明了模型对该区域的置信度越高,研究团队将这种空间重叠定义为模型采样中的区域一致性。
基于这一洞察,研究团队首先设计了一种基于区域一致性进行空间投票的test-time scaling方法——GUI-RC。
首先构建一张与屏幕截图相同大小的投票网格来记录模型每次采样中预测的区域,对于每一个预测结果,将其在网格上对应的区域记上一票,如果模型的预测结果是点坐标,则将其扩展成大小的方框,再投射到网格上。
全部投票结束后,这张网格便记录了模型在采样过程中总体上对每一个像素点的置信度,票数越高的区域代表模型对该区域的信心越强。
随后,提取出网格中票数最高且面积最大的连续区域作为模型采样中的“共识区域”。
最后,利用这块共识区域来进行GUI定位,即可在无需训练的情况下,得到一个更加精确可靠的预测结果。
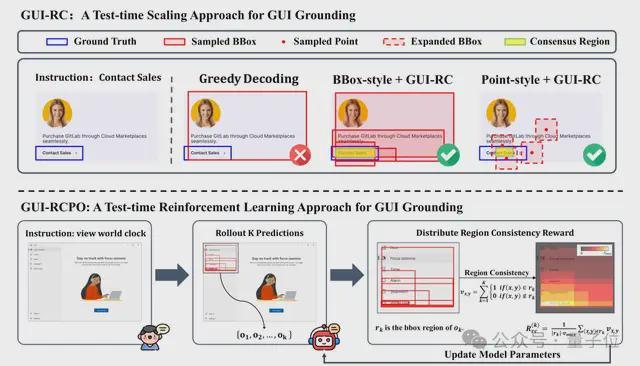
GUI-RCPO:让模型在无标签数据上自我提升
研究团队进一步提出了一种test-time reinforcement learning方法——GUI-RCPO,将模型采样中的区域一致性转换成一种自监督的奖励信号来指导模型的策略优化。
对于每一个预测结果,GUI-RCPO会赋予其预测区域内的平均票数与最大票数之比的奖励,反映出该区域在采样中的一致性程度,一致性程度越高的区域会被赋予越高的奖励。
这样一来,GUI-RCPO便可以在无需任何标注数据和外部监督的情况下,利用这种区域一致性奖励来指导模型进行策略优化,让模型的输出更加精准且自信,进而提高奖励的可靠性和质量,从而实现在无标签数据上的自我提升。
实验分析
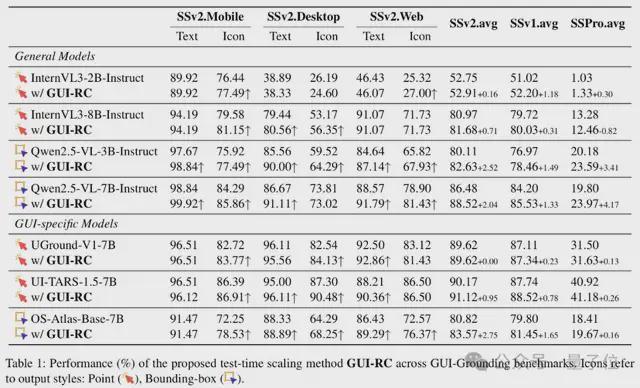
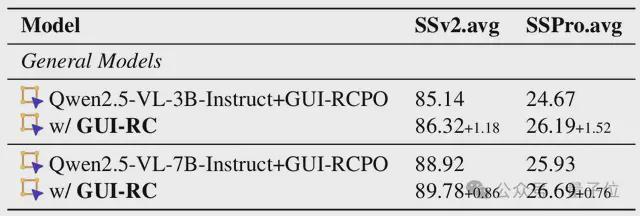
研究团队将GUI-RC和GUI-RCPO两种方法分别应用到不同的通用模型和GUI专用模型上,并在三个主流的GUI定位基准上进行了全面的评估。
对于GUI-RCPO方法,团队使用去掉真值标签的ScreenSpot-v2作为训练数据集。
实验结果表明,两种方法在不同模型上都有一致的提升。
其中GUI-RCPO带来的提升超过了GUI-RC,说明模型在GUI-RCPO训练过程中并不是在简单地拟合共识区域,而是在真正地学会一种更好的定位策略。
此外,GUI-RCPO对于已经在GUI任务上进行过预训练的模型仍然会带来进一步的提升,证明了方法的有效性。
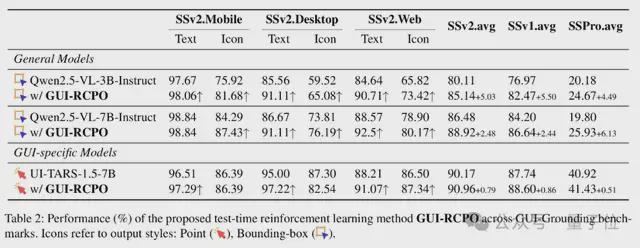
此外,GUI-RCPO还展现出良好的泛化能力,尽管模型只在针对通用场景的ScreenSpot-v2数据集上进行训练,但是在更有挑战性的针对专业场景的ScreenSpot-Pro基准上依然有显著的提升。
并且随着训练步数的增加,模型在三个基准上的表现都有稳定的提升,进一步证明了GUI-RCPO的泛化能力。
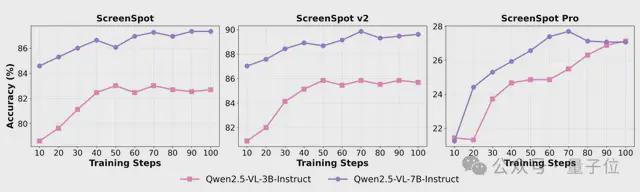
研究团队还尝试在GUI-RCPO训练之后,继续使用GUI-RC进行空间区域投票,并发现模型的表现还能进一步提升,说明通过这种自我强化的循环,模型可以在没有任何标注数据和外部监督的情况下,不断突破预期的性能上限。
案例分析
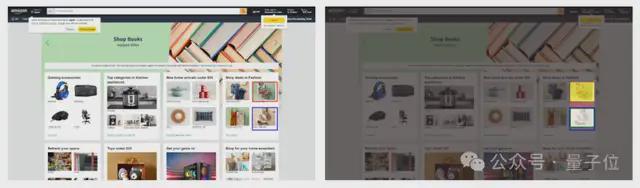
研究团队提供了两个案例,分别展示了GUI-RC可以解决的GUI定位中存在的两类幻觉。
在一个电商界面里,用户指令要求GUI智能体在时尚购物区中查看低于50美元的鞋子(图片中蓝色方框框选的区域),而在贪心解码策略下,模型却被相近的语义与版面布局迷惑,错误地框选到了“低于25美元的上衣”区域(左侧图片中红色方框框选的区域),这是典型的语义错配导致的误导性幻觉。
GUI-RC通过对同一指令进行多次采样,并投票选出采样中的共识区域(右侧图片中绿色方框框选的区域),成功地将模型的注意力稳定地聚合到正确的区域,从而纠正了单次预测的误导性错误,给出更精确的定位。
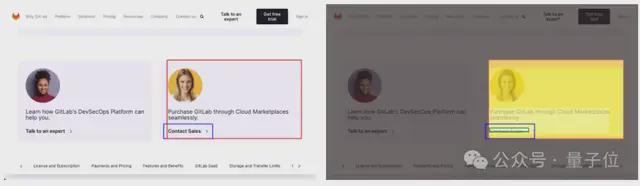
在一个电子平台界面里,用户指令要求GUI智能体“联系销售”(图片中蓝色方框框选的区域),而在贪心解码策略下,模型却把右侧的整张信息卡片当作目标(左侧图片中红色方框框选的区域),而不是精确地框选可点击的“联系销售”按钮。
GUI-RC通过多次采样投票的方式,把一次次略有偏差的预测聚合并提取出一个更加精确、自信的共识区域(右侧图片中绿色方框框选的区域),成功地完成了精准的定位,消除了这类偏差性幻觉。
小结一下
研究团队首先设计了一种无需训练的test-time scaling方法——GUI-RC,通过利用模型在采样过程中呈现出来的空间区域一致性提取出模型的共识区域,从而实现更加精准自信的定位。
为了继续发掘区域一致性的潜力,团队进一步提出了一种test-time reinforcement learning方法——GUI-RCPO,将区域一致性转化为一种自监督的奖励信号,使得模型能够在无需任何标注数据的情况下不断地进行自我提升。
实验证明了该方法有广泛的适用性和良好的泛化能力。
团队的研究揭示了test-time training在GUI智能体领域中的潜力,为构建更加数据高效的GUI智能体提供了一个可行的方向。
论文链接:https://arxiv.org/abs/2508.05615
项目主页:https://zju-real.github.io/gui-rcpo/
代码仓库:https://github.com/ZJU-REAL/GUI-RCPO
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板