
记者 董温淑
编辑 高宇雷
2025年1月,爱奇艺同时陷入了两桩版权争议。
不同的是,其中一桩是爱奇艺被指剽窃,其迷雾剧场的开年大作《漂白》,被指与《南方都市报》早年报道情节雷同。
而另一桩,则是爱奇艺以受害者和原告的身份,诉称“AI六小虎”之一的MiniMax(稀宇科技)在训练过程中采用了爱奇艺拥有版权的视听作品作为素材。
在法律政策已然明确,市场高度成熟的影视领域,《漂白》能否满足相关法规对作品独创性的要求、究竟算不算抄袭,并不难给出定论。

《漂白》剧照,图源/爱奇艺
相形之下,对爱奇艺而言,想要在与MiniMax的争端之中实现自己的权利主张,则是涉入了一条更为未知的道路。
根据公开信息,如今爱奇艺已经于上海市徐汇区人民法院正式提起了诉讼,要求MiniMax停止侵权行为,并索赔约10万元。
就具体侵权内容及诉讼进展,「电厂」分别联系了MiniMax与爱奇艺进行询问,截至发稿MiniMax尚未回应;爱奇艺方面向「电厂」表示,与MiniMax的诉讼目前处于法律流程中,暂时没有更多细节对外公布。

明星AI模型坐上被告席
“每个想法都是一部大片”——这是海螺AI的Slogan。2024年8月31日,MiniMax正式为其上线了视频生成功能,尽管在此之前,Sora、Pika、快手可灵等同类AI视频工具都已发布,海螺AI还是迅速赢得了市场的认可。
由30余家媒体联合发布的“AI产品榜”曾统计,发布仅一个月,海螺AI的月访问量就大涨了860%。另据SimilarWeb显示,至今海螺AI仍保持着极为优秀的数据表现,全球月访问量、平均访问停留时间、跳出率甚至超越了OpenAI旗下Sora、PIKA等同样知名的视频生成网站。
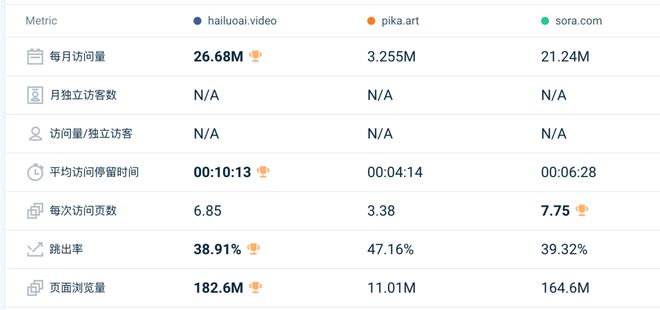
2024年12月三大网站流量数据对比,图源/SimilarWeb
成绩背后,除了MiniMax的主动投放,当然也少不了可圈可点的视频质量。梳理全网用户点评,许多人认为海螺AI生成的视频内容展现出了极高的稳定性、逼真的情感表达、真实流畅的动作和光影表达……
但随着爱奇艺提起诉讼,“这款明星应用诞生背后是否存在灰暗面?”的疑问,被抛入了视线之中。
一位不愿具名的律师对「电厂」分析道:“根据现有信息可以推测,是MiniMax用爱奇艺的版权作品投喂了前者旗下的海螺AI。正因为与之前的奥特曼案不同,这个案件非常独特,最近也引起了法律业界的讨论。”
他提及的“奥特曼案”,是指广州互联网法院于2024年2月判决生效的一桩案件。在这一案件中,被告公司的网站能够生成奥特曼形象的相关图片,而原告上海新创华公司是国内奥特曼系列的形象代理商。最终法院认为,被告侵犯了新创华对奥特曼形象的复制权和改编权。
然而,海螺实际上无法直接生成涉及爱奇艺版权的内容——「电厂」曾经在海螺AI中,用多部爱奇艺旗下剧集名称及一张相应剧照作为输入,但最终生成的人脸形象均与原始剧集大相径庭。
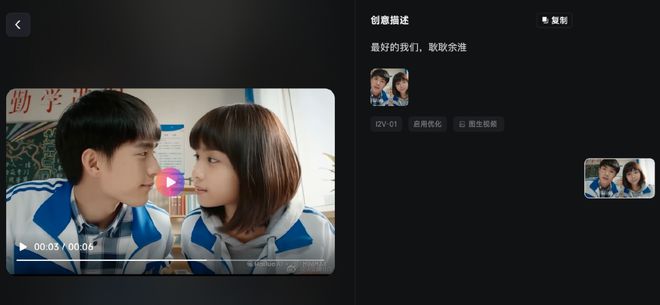
用爱奇艺旗下剧集关键词输入海螺AI生成内容
“(所以)侵权事实并没有那么明确和显然。但是爱奇艺既然能提起诉讼,说明它可能已经通过技术手段固定了一些证据,比如证明了有爬虫爬取自己平台的内容。”前述律师讲道。
在他看来,爱奇艺对MiniMax的诉讼更揭示了一片法律空白的存在——AI训练语料的著作权如何确认?训练一方下载相关内容到自己的服务器上是否涉及复制权?训练方将下载的内容经过压缩等处理投喂给大模型,又是否涉及改编权?
针对这些问题,目前既无明确的法律规定,类似判例也并不多。这让作为新生事物的大模型在历经了两年有余的高速增长之后,终于被踩下了一脚“技术合规”的刹车。

频发的纠纷,缺失的政策
“没有听说过哪家独立大模型公司给视频平台(的版权内容)付费的。”一家卡通人物形象视频AIGC应用创业者对「电厂」讲道。
“(相比训练环节)版权合规更多发生在生成环节,比如用户去各个模型里输入雷军马云马化腾,肯定是无法生成出相应名人的视频内容的。”他补充道。
直到纠纷和争议真正来临,许多人才意识到过往在追求大模型极致性能的路上,还存在着一个终有一天要直面的问题。
“在AI的大时代真正来临的时候,第一个迎接我们的,一定是大量的诉讼。”全球顶尖视效企业数字王国的CEO谢安曾这样告诉「电厂」,“而如今为什么这种诉讼还没大规模开始,是因为还没有人真正在AI上赚到钱。”
中国人民大学国家版权贸易基地日前发布的“2024数字版权保护与发展年度关键词”中,也将“AI大模型语料训练版权挑战”位列于八大关键词中的第三位。
但即便走到对簿公堂,哪一方的主张能够得到支持,仍旧是个未知数。
爱奇艺对MiniMax的起诉,是国内视频平台起诉大模型创企侵权的“第一案”。但在全球范围内,这类纠纷并不鲜见。
早在2023年12月,全球AI芯片龙头英伟达就陷入了版权官司,分别名为Brian Keene、Abdi Nazemian和Stewart O'Nan的三位作者诉称,英伟达未经授权使用了三位作者的版权书籍,用于训练AI模型“NeMo”。至今,案件仍在审理过程中。
2024年3月份,谷歌被曝因为在未经许可的情况下,使用法国新闻机构和出版商生产的内容训练其旗下AI大模型Bard,被判违反欧盟版权法,并被处以2.5亿欧元罚款。
图源/网络
而全球知名的大模型创企、Claude 模型母公司Anthropic,与环球音乐等音乐出版商之间的著作权纠纷已持续了14个月之久,在刚刚过去的1月2日才刚刚完成了初步协议。纠纷的焦点,同样包含训练语料的著作权问题,Anthropic被指使用了“无数”受版权保护的歌词,用于训练对话模型……
天元律师事务所律师、曾亲历“国内AI图片侵权第一案”的李昀锴向「电厂」解释了这背后的技术与法律困境:“通过训练数据,最终是形成了AI模型,但是在这个模型里面,它最终并不会完全保留训练的数据,而是把训练语料的其中一些元素存储为向量数据集里面的一个向量数据,但这个向量数据它本身是无法逆向去做还原的,也就是没有办法从这个向量数据去确定最早使用的是哪一个作品,这样的话语料的权利人维权是非常困难的。”
而对于模型训练一方来说:“如果在训练学习完成之后,没有保留最早的训练数据集,可能训练方都不知道我最早到底使用了哪些训练数据,因为我只有一个最终的向量数据集,所以举证责任从技术上是很难去实现的。”李昀锴分析道。

技术发展带来的问题,不只靠技术解决
目前,全球AIGC领域法律规范普遍处在建设阶段,针对训练数据环节,不同国家和地区的规范也存在差异。
比如,日本对AI训练用的数据不做强制著作权保护,并允许AI使用任何数据,“无论是非营利还是商业目的,无论是复制之外的行为,还是从非法网站或其他途径获得的内容”。
2024年上半年,美国众议员曾提出一项新法案,要求在AI 模型在向消费者提供之前的30天内,需要向版权局提交该模型训练数据集中受版权保护作品的完整清单,并且当现有模型的训练数据集“发生重大改变”时,也必须及时向版权局提交,以在保障创新的同时保障创作者的权利和贡献。
英国、法国、德国等欧洲国家,则在版权法中增设了“文本数据挖掘”的例外条款,允许行为人出于非商业目的,对合法获取的作品进行文本与数据挖掘,但是行为人不能将其所用的信息转让给他人或进行其他处理。
而国内2023年发布的《生成式人工智能服务管理暂行办法》在第七条中,也对AI训练数据的使用作出了相应规定。

图源/国务院网站
但即便相关法律规范在逐步成型,维权的时间和金钱成本仍不可小觑。就像谢安对「电厂」说到的:“就算你可以在法律上面有制高点,在大型诉讼之下,到最后就算等来了法律的明文保障,诉讼所花费的两三年、三四年所带来的时间及衍生成本,你能怎么办?”
正因如此,许多平台实际上在自我摸索可行的规避风险方式。在海螺AI的用户协议中,写有这样一句话:“为保护文学、艺术和科学作品作者的著作权,以及与著作权有关的权益,我们高度重视知识产权,并尽量避免侵犯他人合法权益。但是作为问答基础服务的提供者,我们每天会收到大量的用户上传的内容并进行改善我们的算法。”

随着AIGC市场逐渐成熟,越来越多的开发者意识到自己所生产的内容可能会在不知情的情况下被投喂给大模型,其中一部分人开始选择同样借助技术的手段规避这一情况。
比如,有的人会采用“数据投毒”的方式,在可能成为训练数据的作品中植入恶意样本或修改数据,以欺骗机器学习模型。
也有一部分人开始“逃离”平台,只为规避自己的作品被投喂AI的可能性,从2023年开始,许多原画画师离开了小红书、网易旗下LOFTER AI等作品分享平台。
总而言之,要改变训练数据的著作权困境,既需要法律补位空白、产业形成规范,也需要每个人在意识层面构筑新的“围墙”。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板