
5 月 14 日凌晨,OpenAI 发布了一个新模型——GPT-4o。
对,不是搜索,不是 GPT-5,而是 GPT-4 系列的一款全新多模态大模型。按照 OpenAI CTO 米拉·穆拉蒂(Muri Murati)的说法,GPT-4o——「o」代表了 omni(意为「全能的」)——能够接受文本、音频和图像任意组合的输入与输出。
而新的 GPT-4o 模型响应更快、处理更快、效率更高,也让人机交互在一定程度上发生了质的变化。
事实上,在不到 30 分钟的发布会中,最为人津津乐道的不是 GPT-4o 这个模型自身,而是在 GPT-4o 的支撑下,ChatGPT 的交互体验。不仅是人机语音对话体验更接近人与人之间的实时对话,视觉识别能力的进步也让 AI 更能基于现实世界进行语音交互。
简而言之就是更自然的人机交互。这很容易让人想起《她(Her)》中的 AI 虚拟助手,包括 OpenAI CEO 山姆·奥尔特曼(Sam Altman):
但对很多人来说,更重要的可能是免费用户也能使用 GPT-4o(不包括新的语音模式),官方说将在接下来几周正式推出。当然,ChatGPT Plus 付费用户显然还是有「特权」的,从今天开始就可以提前试用 GPT-4o 模型。
不过 OpenAI 演示中的桌面应用还未上线,ChatGPT 移动端 APP(包括 Android 与 iOS)也还没更新到发布会演示的版本。总之,ChatGPT Plus 用户暂时还体验不到的 ChatGPT(GPT-4o)新的语音模式。
所以在某种程度上,目前 ChatGPT Plus 用户享受到的 GPT-4o 基本是未来几周 ChatGPT 免费版用户的体验。
但 GPT-4o 的实际表现如何?值不值得免费版用户重新开始使用 ChatGPT?说到底还是需要实际的上手体验。同时,通过目前基于文本和图像的对话,我们或许也能窥见新 ChatGPT(GPT-4o)的能力。
从一张图片中看出《原神》,GPT-4o 更懂图像了
GPT-4o 模型的所有升级,其实都可以总结为原生多模态能力的全面提升,不仅是文本、音频和图像任意组合的输入、输出,同时各自的理解能力也有明显的进步。
尤其是图像理解。
在这张图片中,有被部分遮挡的书本,还有一台正在运行游戏的手机,GPT-4o 不仅能准确识别书本上文字,根据知识库或者联网正确地识别出完整的书名,最让人惊艳的是能直接看出手机正在运行的游戏——《原神》。

图/ ChatGPT
坦白讲,熟悉《原神》这款游戏的玩家大概都能一眼看出本体,但仅凭这张图片,很多没玩过游戏、不了解游戏角色的人基本都认不出《原神》。
当小雷询问 ta 怎么看出是《原神》时,GPT-4o 的回答也符合逻辑:无非就是画面内容、游戏界面以及视觉风格。

图/ ChatGPT
但同样的图片和问题,但我询问通义千问(阿里旗下)和 GPT-4,它们给出回答却很难令人满意。
类似的,在看了马斯克刚发的梗图之后,GPT-4o 也能较为准确地理解其中的笑点和讽刺之处。
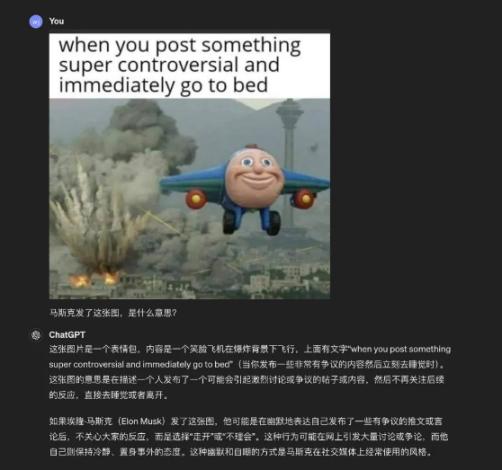
图/ ChatGPT
而在移动端 ChatGPT APP 上,通过一张非常局部的拍摄照片,GPT-4o 对场景的描述也算准确,并且也大致推理住宅区或者办公楼等范围。

图/ ChatGPT
以上这些例子,其实都能在一定程度上说明 GPT-4o 在图像理解方面的进步。需要一提的是,根据 OpenAI 新的政策,几周后免费版 ChatGPT 用户也支持直接拍照或者上传图片给 GPT-4o。
此外,免费版用户在使用 GPT-4o 时,还能使用通过上传文件帮助总结、撰写和分析。不过从文件个数和大小上,ChatGPT 可能还是不如 Kimi 或者其他国内 AI 聊天机器人大胆,限制明显。
当然优点还是有,毕竟 GPT-4o 有着 GPT-4 的顶级「智能」。
新模式还没来,但语音体验已经上了一个台阶
但比起图像理解能力,在小雷看来,这次 GPT-4o 最重要的能力升级还得是语音。
虽然新的语音模式还没实装,很多演示中的体验都没办法感受,但打开现有的语音模式聊几句,就能发现 GPT-4o 的语音体验已经有明显的升级。
其一,不仅音色音调非常接近正常人的声音,更关键的是 AI 也能熟练掌握各种语气词,比如「嗯」「啊」等,对话中也会有一定的抑扬顿挫。与此相对的,能明显感受到,GPT-4o 下语音模式的回应更接近普遍意义上的「有感情」。
相比 Siri 等语音助手理所当然有大幅的进步,甚至比起目前一堆的生成式 AI 语音聊天,GPT-4o 下语音也显得更加保真和自然。
其二,过去在语音模式的对话中,说完话往往需要较长的时间才能让 ChatGPT 意识到我说完了,然后开始上传、处理和输出回答,以至于很多时候我会选择手动控制。但在 GPT-4o 下,ChatGPT 能够更灵敏地意识到我说完了并开始处理,基本就少了很多手动干涉。

目前还是旧的语音模式和界面,图/ ChatGPT
不过缺点也有,有些小雷估计正式推出时也很难有明显的改善,比如一直在讨论的「幻觉」问题,并没有感受到明显的改善;但有些可能将在推出发生质的改变,比如对话的延迟。
从目前版本的体验来看,就算在聊天模式下网络连接一切正常,语音模式一开始连接就会花费不短的时间,甚至是连接失败。但即使连接上了,对话延迟还是很高,经常是我说完了要等待数秒才能等到语音回应。
实际上,旧的语音模式其实是先将用户的语音通过 OpenAI 的 Whisper 模型转录成文本,再通过 GPT-3.5/GPT-4 进行处理和输出,最后再通过文本转语音模型将文本转录为语音。这么一通下来,也就不难理解之前 ChatGPT 语音回答之慢、语音交互体验之差的的原因了。
同时,这也是新的语音模式让人期待的核心原因。按照 OpenAI 的说法,GPT-4o 则是跨文本、视觉和音频端到端训练的新模型,在新的语音模式下所有输入和输出都由同一个神经网络处理。甚至不只是文本和语音,新的语音模式还能基于手机摄像头的实时画面进行对话。

新的语音模式和界面,图/ OpenAI
简单来说,原来 ChatGPT 回应你的语音必须要依序经过三个「脑」(模型)的处理和输出。而在即将到来的新模式下,ChatGPT 只要经过一个同时支持文本、语音乃至图像的「大脑」(模型),效率提升也就自然可以想象了。
至于到底能不能实现 OpenAI 演示中的超低延迟回应,还是要等未来几周新模式的实装,届时小雷也会在第一时间进行体验。
诚然,在 GPT-4 发布以来的一年里,全球大模型还在疯狂涌现和迭代,与 GPT-4 之间的差距也在不断拉小,甚至一度超越(Claude 3 Opus)。但从权威基准测试、对战 PK 排行榜以及大量用户的反馈来看,GPT-4 依然是全球最顶级的大模型之一。
更重要的是,技术塑造能力,产品塑造体验。GPT-4o 再次证明了 OpenAI 依然在技术和产品上的绝对实力,而 GPT-4o 对于语音交互体验的迭代,恐怕还会再次消灭一批 AI 语聊、AI 语音助手方向的创业公司。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板