
导读
TP 与 AP 融合的 HTAP 数据库正成为业内的发展趋势。但由于大规模数据场景下 TP 与 AP 系统本身的复杂性,要在一套数据库系统中融合两种使用场景的功能并不容易。浪潮推出的 HTAP 数据库 ZNBase 采用多模存储引擎的方案实现 HTAP 特性,在 OLTP 的基础上引入列存引擎支撑 OLAP 场景。本文将着重介绍列存引擎技术在 HTAP 数据库 ZNBase 中扮演的重要角色。
名词释义OLTP,全称 On-Line Transaction Processing,翻译为联机事务处理OLAP,全称 On-Line Analytical Processing,翻译为联机分析处理
从上个世纪 60 年代开始,计算机系统就被人们用于执行薪资结算、会计和计费等领域的任务。那时,用户输入数据,计算机系统再对数据进行处理,从而完成一系列的增删改查操作,这就是早期的 OLTP 。随着计算机技术与数据库技术的进一步发展,OLTP 在政府、银行和企业信息系统中被广泛应用至今。如今,OLTP 被认为是一种低延迟、高容量、高并发工作负载,通常用于开展业务,例如接订单和履行订单,进行装运,为客户开账单,收款等事务处理。
而 OLAP 被认为是分析工作负载。OLAP 面对的场景是相对较高的延迟,较低的数量和较低的并发工作负载,这些负载通常用于通过分析运营,历史和大数据,制定战略决策或采取措施来提高公司绩效,提升产品质量,改善客户体验,进行市场预测等。随着近年来大数据技术的兴起,企业对数据分析的场景在时效性方面有了更高的要求,大规模数据下的 OLAP 也开始成为众多企业的刚需。
在互联网流量爆发之后,在面对海量数据时,OLTP 和 OLAP 系统的信息体系结构和基础结构各不相同,同时又具备各自的复杂性,因此这两种应用场景分别有不同的产品来满足用户需求。这一时期,企业通常采取“事务型数据库系统+分析型数据库系统+ETL 工具”的组合方案来实现大规模数据存储事务+分析的业务需求。
这种采用不同系统来针对不同场景进行数据处理的方案也带来了相应的难题。因为 TP 和 AP 是跨平台的,所以在搭配使用时就会有数据传输的过程,这就带来了两个挑战:数据同步、数据冗余。
数据同步的核心是数据时效性问题,过期的数据往往会丧失价值。以往的做法是,OLTP 系统中的数据变化,通过日志的形式暴露出来;通过消息队列解耦传输;后端的 ETL 消费拉取,将数据同步到 OLAP 中,形成一套 TP 到 AP 的数据传输链条。由于整个链条较长,这就对时效性要求较高的场景提出了考验。
另一方面,数据在链条中流动,存在多份的数据冗余保存。在常规的高可用环境下,数据会进一步保存多份。因此带来了更大的技术、人力成本以及数据同步成本。同时横跨如此多的技术栈、数据库产品,每个技术栈背后又需要单独的团队支持和维护,如 DBA、大数据、基础架构等,这些都带来了巨大的人力、技术、时间、运维成本。
2014 年,Gartner 提出了一种混合事务/分析处理的新型数据库模型 HTAP,旨在打破 OLTP 与 OLAP 系统间的隔阂,将二者融合到一个数据库系统中,避免 ETL 跨平台数据传输带来的高昂成本。
随着软硬件基础设施和数据库技术不断发展,兼顾 OLTP 和 OLAP 负载的 HTAP 数据库系统逐步替代传统“事务型数据库系统+分析型数据库系统+ETL 工具”方案的趋势已经形成。
ZNBase 是由浪潮于近期开源的一款 HTAP 分布式数据库,也是首个即将被开放原子开源基金会接纳的国产数据库项目。该数据库系统为应对日益剧增的混合负载场景研发,能够混合事务和分析场景,适用更多数据应用需求。为实现 HTAP 的特性,该数据库系统中的列存引擎子系统在整个系统架构中扮演了重要的角色。
支撑 ZNBase 的 HTAP 功能的是多模存储引擎,在其中结构化数据的处理上,存储可以分成行存和列存,是分别针对 OLTP 和 OLAP 场景的优化,而支撑 OLAP 场景的就是的列存引擎。
列存引擎是 ZNBase 数据库系统 HTAP 形态的核心组件,用于存储和管理数据的列存副本,是行存引擎的扩展,列存引擎在提供良好隔离性的同时,也兼顾了读时强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引方式达到 Learner 和 Leader 的同步。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题。
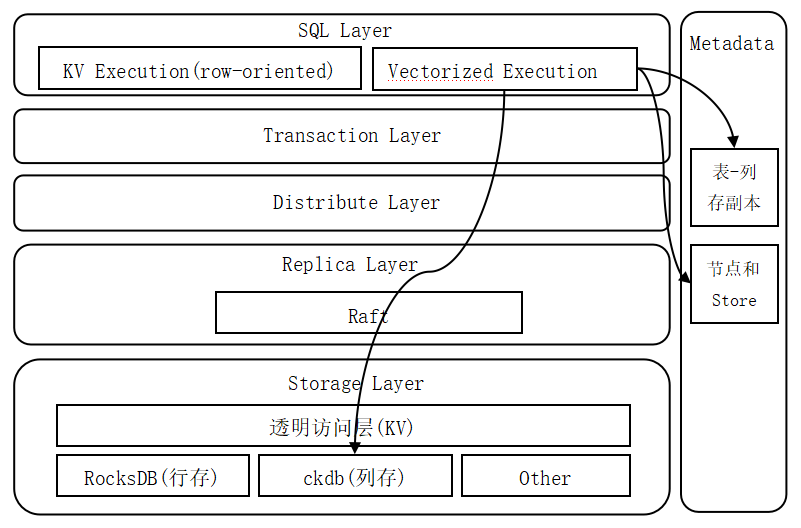
列存引擎逻辑架构包含四个部分:
1) DDL 模块;
2) SQL 层矢量计算模块;
3) 副本层 Raft 协议模块;
4) 存储层的透明访问模块和列存数据库模块。
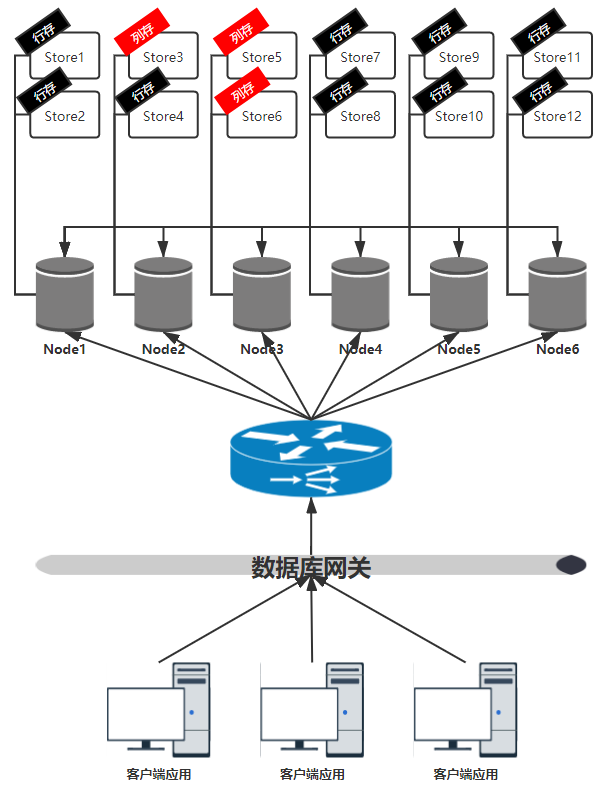
列存引擎的物理架构分为三层:
1) 应用层:包括所有调用数据库服务的客户端应用程序;
2) 网关层:数据库网关负责通过优化 SQL 路由,提升集群整体执行性能。数据库集群采用全对等网络拓扑,集群中的任何一个节点实例都可以处理 SQL,数据库网关根据节点实例负载和数据分布情况对 SQL 路由进行优化,将 SQL 发送给较为合适的节点实例,例如将纯 OLAP 负载发送到某一组列存节点上。
3) 集群层:集群由角色和作用相同的多个节点实例组成,接收 SQL 的实例节点临时充当 Master 的角色,负责驱动 SQL 的执行流程,与其他节点实例交互,并返回计算结果。每个节点实例可拥有多个 Store,每个 Store 可以被标记为不同的类型,目前可标记行存 Store 或列存 Store。列存 Store 底层采用列存数据库,只能存储列存副本。如果节点实例拥有的 Store 均为列存,则成为列存节点实例。从资源隔离的角度出发,可以将所有列存节点实例组成一个虚拟 OLAP 数据库集群,专门负责处理 OLAP 负载,且不对其他行存节点实例造成过大影响。
列存引擎有几大功能特性,矢量计算、计算下推、列式存储和异步复制。

在具体实现上,列存引擎采用了 Clickhouse 并在其基础上进行吸收优化。ClickHouse 本身是一套高效的列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL 等丰富功能。
作为一款新型的 HTAP 分布式数据库系统,ZNBase 可以同时满足事务、分析场景,避免繁琐且昂贵的 ETL 操作。而列存引擎技术在这其中发挥了重要的作用。
列存引擎作为实现 HTAP 的关键技术,其异步复制功能可以在保证事务处理性能的基础上,达到分析场景准实时的效果,满足用户需求,优化用户体验。列存引擎植根于 ZNBase 数据库中,继承其强大的产品特性,使得其在原有高性能的 OLTP 能力基础上,增强了对 OLAP 场景的处理能力,丰富了产品功能。
对于大部分数据库用户来说,最好的产品体验就是开箱即用,无论是 TP 还是 AP 场景,如果能够在同一个黑盒系统中完成所有操作,就能降低用户心智负担和运维成本。所以不难理解为何统一 TP 和 AP 处理的 HTAP 数据库能够成为受市场和用户追捧的产品趋势。
关于 ZNBase 的更多详情可以查看:
官方代码仓库:https://gitee.com/ZNBase/zn-kvs
ZNBase 官网:http://www.znbase.com/
对相关技术或产品有任何问题欢迎提 issue 或在社区中留言讨论。同时欢迎广大对分布式数据库感兴趣的开发者共同参与 ZNBase 项目的建设。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板