针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。
该论文详尽阐述了以潜空间推理增强与自蒸馏训练为核心的端到端演进方案,创新性地提出了思维增强的复杂查询理解、推理内化的自蒸馏训练 pipeline,以及基于真实用户行为反馈的偏好对齐优化体系的原生化设计。
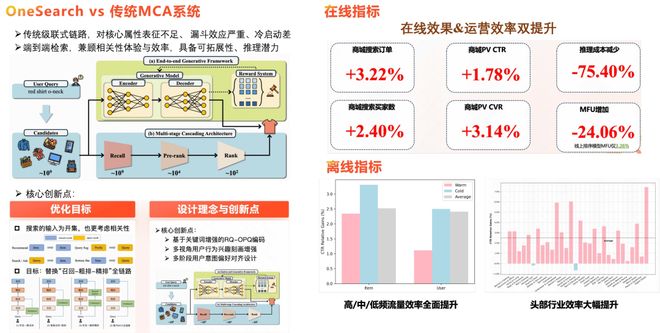
目前,该系统已在快手电商搜索平台全量上线,在不增加任何推理成本与服务时延的前提下,取得了商品 CTR 提升 3.98%、买家数提升 2.07%、订单量提升 2.11% 的显著业务收益,并有效缓解了搜索系统长期存在的信息茧房与长尾稀疏问题。

一、背景
1.1 OneSearch V1 回顾与成果
OneSearch V1 通过端到端生成式架构在显著降低推理成本的同时,大幅提升了中高频query 的在线效果与转化效率,尤其是针对中高频的 query 和中长尾用户偏好的推理能力有着比较显著的提升(OneSearch:电商搜索端到端生成式建模)。
1.2 V1 仍存在的核心瓶颈
随着用户偏好日趋多样化、搜索 query 日益复杂,我们识别出制约 OneSearch 进一步提升的三个关键限制:
1.3 OneSearch V2 的核心思路
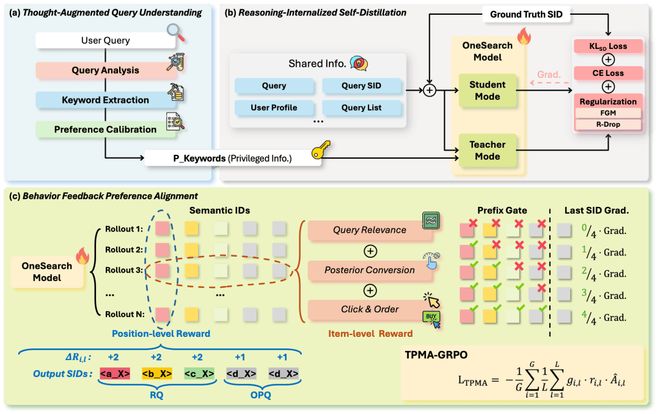
针对上述瓶颈,OneSearch V2 提出Latent Reasoning Enhanced Self-distillation(基于自蒸馏隐式推理增强)框架:
二、实验方案
2.1 编码方案(沿用 V1)

OneSearch-V2 中沿用 V1 的编码方案 KHQE+RQ-OPQ。
近期研究将 SID 编码方法分为单模态与多模态两类。不同于推荐系统,搜索引擎需在统一分词体系下对齐 query 与商品,保障语义约束的鲁棒性,这对单模态 query 与多模态商品(含文本、多视角图片、讲解视频)间的表征差异提出精细建模要求。V1 采用 Qwen-VL 从多源信息中提取商品核心关键词,构建统一文本表征;其他方法则尝试联合输入或多模态分别编码后拼接。但多图易呈现互斥属性(如连衣裙不同颜色),冗余属性(如 T 恤纽扣数量 / 位置)易引入偏差,导致关键属性被淹没。为此,V2 开展大量实验,系统评估不同编码范式在电商生成式搜索中的适用性。
为全面比较多模态与单模态 embedding 的效果,我们在多种模型配置下开展了对比实验,包括:
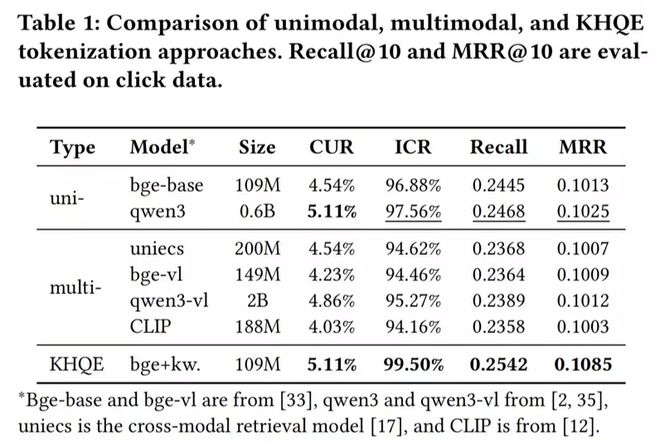
为简化实验,我们收集约 500 万条线上点击的 < query, item > 对,商品输入仅含标题和两张主图;所有 embedding 统一采用 RQ-OPQ 分词。结果表明:单模态方法显著优于多模态(如小规模 bge-base 优于大规模 Qwen3-VL),主因跨模态表征差异与冗余属性削弱了多模态编码有效性;“先分离后拼接” 策略表现最差,进一步验证该挑战;KHQE 效果最佳,兼具强关键属性提取与层级表征能力,且模型轻量,支持实时 query 处理,在性能与效率间取得良好平衡。结论指出:电商搜索编码需聚焦两大关键 —— 缓解跨模态差异、增强关键信息。
2.2 Thought-augmented Query Understanding(思维增强的 query 理解)
2.2.1 动机
电商搜索引擎日均处理海量 query,用户意图复杂:头部 query(如 “室内健身器材”)表达模糊、意图发散,导致候选过宽;尾部 query 类型多样(问答 / 推荐 / 排行榜 / 知识 / 否定 / 平替等),语义约束强、行为信号稀疏,意图识别与商品匹配难度高。在快手商城,此类复杂 query 占 PV 约 1/3,但转化率仅 8%,效率偏低。OneSearch-V1 通过表征对齐与增强缓解语义鸿沟,但 CTR 增益呈 “倒 U 型”,头部与尾部提升有限 —— 头部瓶颈在于 “检索哪个”,尾部在于 “能检索什么”。显式 CoT 虽提升可解释性,但输出冗长、小模型难复现;SID 与文本 CoT 异构性强;且电商更需聚焦意图对齐的关键词,而非全链路推理。亟需轻量、高效、意图导向的语义增强方法。
2.2.2 思维增强 pipeline
我们基于 Qwen3-32B 在语义约束下生成精准 CoT,提取高信息密度关键词(确保意图、类目、属性一致),作为训练阶段的补充语义信号,提升 query 意图识别与用户偏好校准;同时以关键词驱动 CoT,显著降低推理开销。整体采用三步推理 Pipeline。
Step 1. query 分析。包含四个组成部分:
Step 2. 关键词提取。针对商品检索意图的 query,从分析结果中提取关键词,并施加意图、类目与属性一致性约束;再经同义合并与冗余剔除,最终按商品热度降序输出;其余意图 query 由专用引擎处理,Pipeline 直接终止。
Step 3. 偏好校准。基于用户画像与历史行为(如搜索词、交互商品序列),LLM 动态感知偏好,对关键词集合进行个性化过滤或增补;训练时注入当前会话已交互商品作为强信号,确保关联真实标注商品的关键词被保留或显式引入。
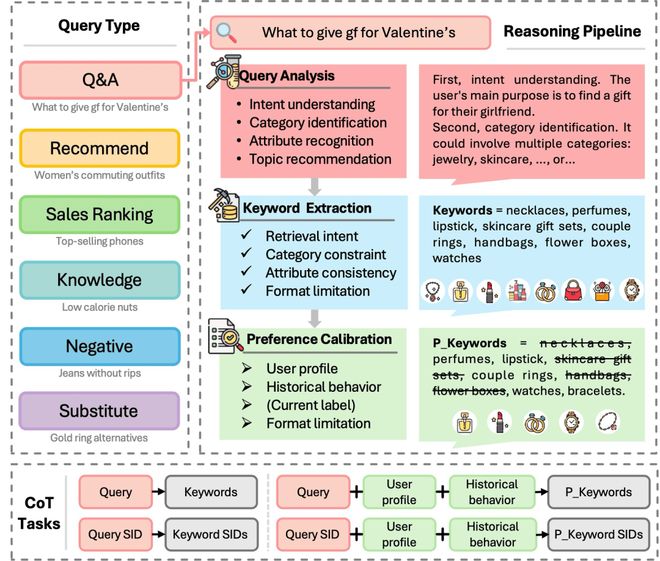
2.2.3 部署方式
上述第二步和第三步构建 < query, keywords > 和 < query, user, keywords > 训练语料;设计 4 个 CoT 任务,融入 OneSearch-V1 SFT 第一阶段(语义对齐),使模型超越日志学习 query 知识,并结合用户偏好挖掘其感兴趣的商品话题,提升复杂性与个性化推理能力;在线部署时,关键词驱动的 CoT 生成异步执行,结果用于流式训练与近线推理;相同 query 或 < query, user > 可复用缓存,显著降低算力开销且零延迟。
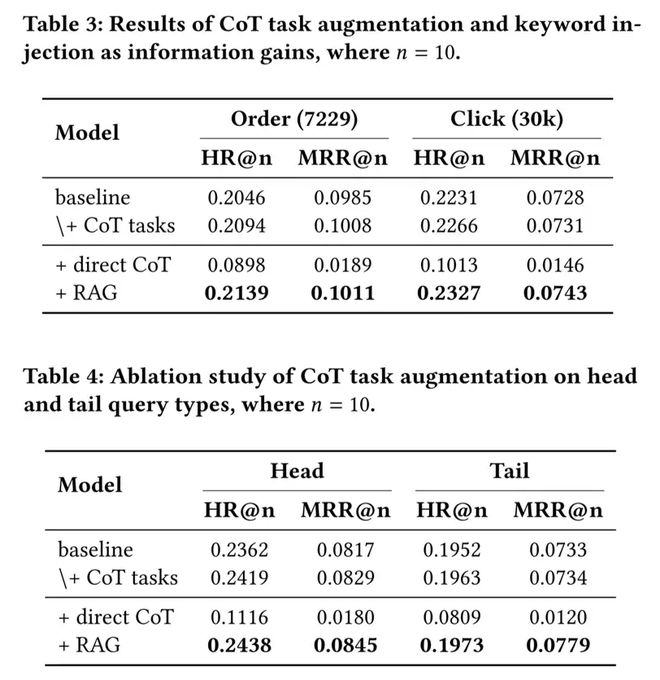
注:"\+" 表示在前一行模型基础上累加新组件(逐步叠加),"+" 表示在 CoT tasks 完成后的模型上单独添加组件。
结果显示:在规模相当时,单模态显著优于多模态(即使小规模的 bge-base 也优于更大规模的 Qwen3-VL),这源于跨模态表征差异与冗余属性;先分离后拼接策略表现最差,进一步印证上述挑战。KHQE 取得最佳结果,展现出卓越的核心属性提取与层级表征能力;其较小规模还支持实时处理 query,在性能与效率间达成良好平衡。这也印证了电商搜索编码的两个关键点:缓解跨模态差异、增强关键信息。
2.3 Reasoning-internalized Self-distillation(推理内化的自蒸馏)
2.3.1 动机:保留推理增益,消除推理开销
直觉方案(OneSearch 先生成推理关键词再生成 SID)因离散 SID 与文本关键词表征异质性强,小模型难以建模,实验显示显式 CoT 推理反而显著降低性能,甚至不如 baseline。替代方案(将关键词作为 query 补充信息 + RAG)虽提升检索与排序效果,但需在线调用 thought-augmented query understanding 模块,带来不可接受的延迟,不满足电商搜索严苛的实时性要求;且关键词覆盖有限,易导致模型仅聚焦于关键词显式涵盖的商品,泛化能力受限。
核心问题:能否保留甚至进一步增强推理带来的性能增益,同时不承担推理带来的开销?
2.3.2 自蒸馏的核心机制
我们提出推理内化自蒸馏机制,将关键词引导的深思型 CoT 推理能力直接编码至模型参数,转化为快速直觉式推理;无需修改架构、不增参数、不加推理 token,仅通过定制化蒸馏将推理能力注入原模型权重。
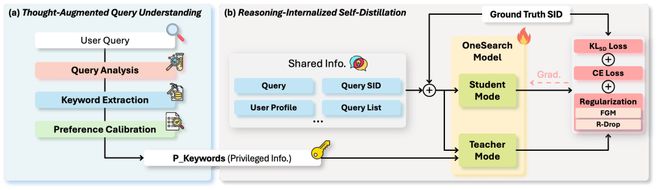

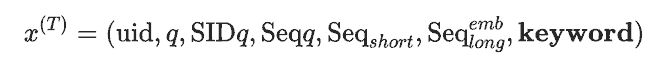
学生接收不含关键词的相同输入:
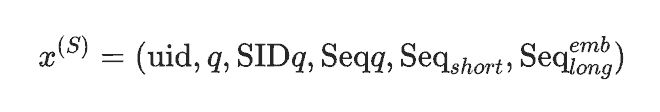


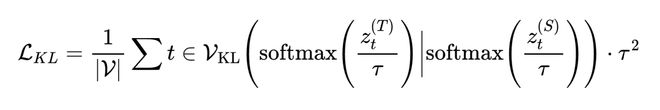

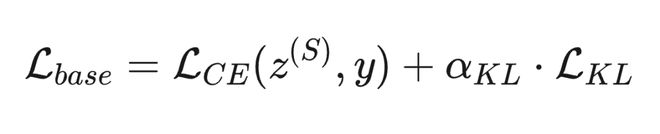
为验证自蒸馏相对于其他推理内化方案的优越性,对比了四种替代策略:
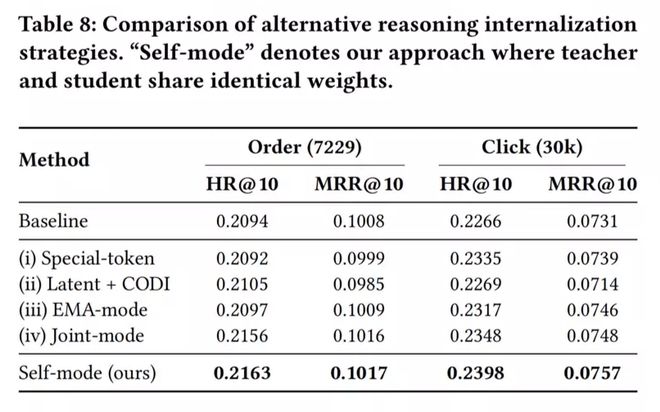
教师与学生之间的信息不对称引入根本性挑战:学生必须从严格更少信息的输入中产生同样自信的预测,这迫使损失曲面在关键词缺失输入的邻域变尖锐:嵌入空间的微小扰动可能导致输出分布不成比例的大变化。我们识别出两种互补失败模式,并用针对性正则化应对:

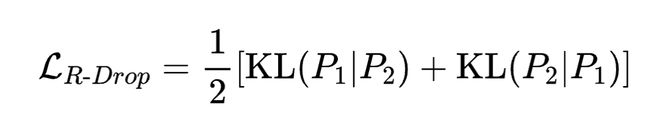
输入鲁棒性:FGM 对抗扰动。 补充 R-Drop 的输出空间正则化,我们对输入嵌入空间应用 FGM。第一次反向传播后,沿梯度方向扰动共享嵌入层:
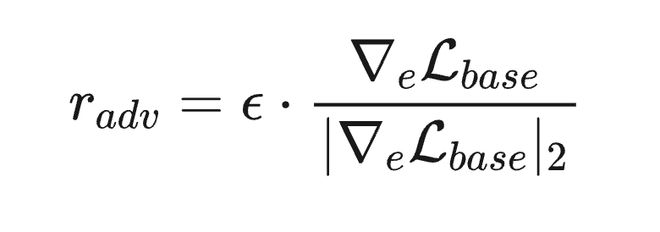

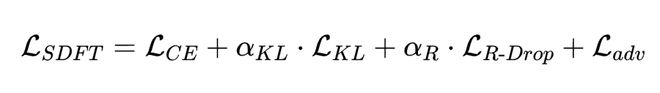
此外,用 focal loss 替换标准交叉熵,缓解 SID 词表中的长尾类别不均衡问题。
2.3.3 关键实验结论
2.4 Behavior Feedback Preference Alignment(行为反馈偏好对齐)
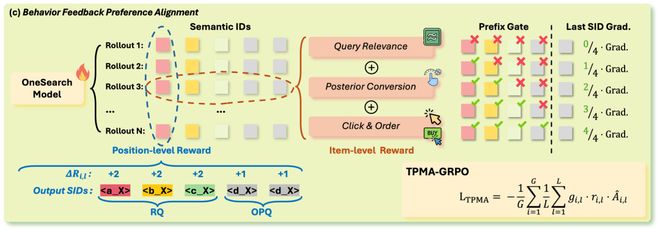
2.4.1 动机:替换独立 Reward Model,直接利用用户行为反馈
OneSearch-V2 以直接行为反馈替代独立 Reward Model,构建偏好对齐系统:
2.4.2 复合奖励设计

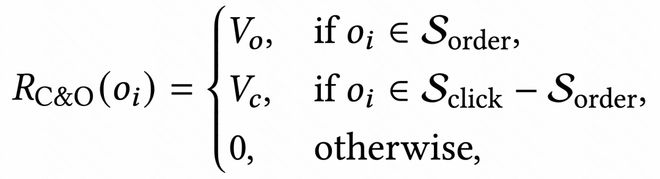

2.4.3 标准 GRPO 及其局限

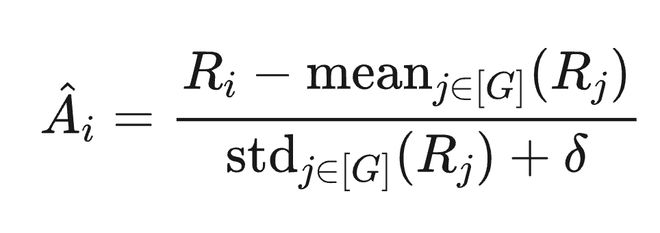

2.4.4 TPMA-GRPO:Token-Position Marginal Advantage
为解决信用分配问题,提出 TPMA-GRPO,将序列级奖励分解为位置级边际贡献,并基于前缀正确性门控梯度流。

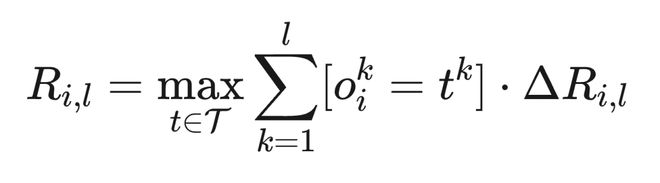


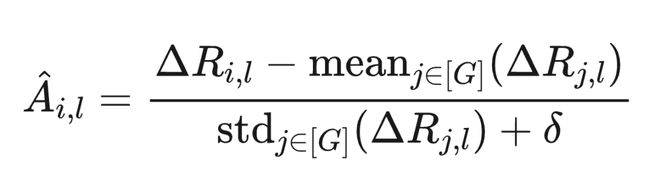


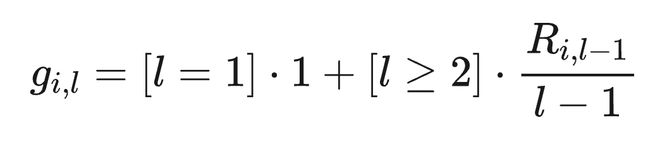

该机制自然实现了层次化课程学习:模型先学习生成正确的粗粒度 token,再训练细粒度 token。

使模型同时学习生成什么(通过 TPMA)和生成的价值(通过商品级奖励)。
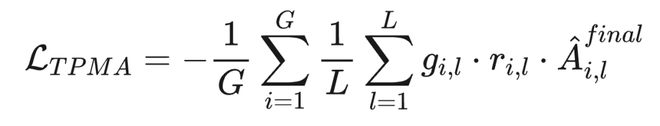

三、效果评测
3.1 离线效果评测
3.1.1 主实验
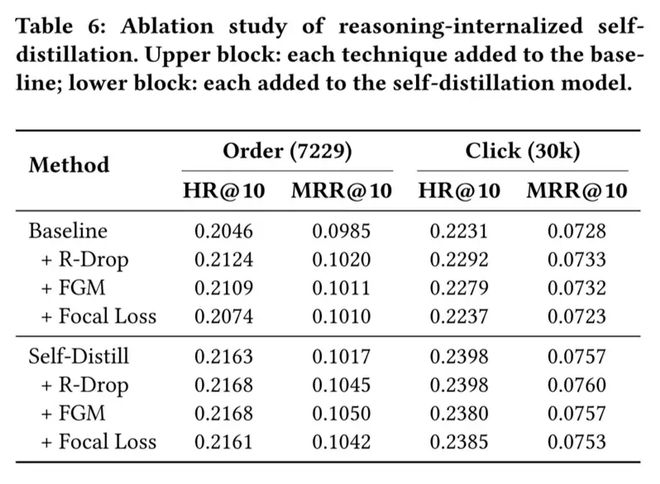
我们从用户搜索日志中选取 30,000 个有有效交互的 PV 作为测试集,包含 30,000 次点击与 7,229 次下单。对每个 PV 提取 Top-10 生成商品进行公平对比,所有模型基于相同原始预训练模型训练,采用 HitRate@10 与 MRR@10 评估。离线实验分为 SFT 阶段逐步优化、RL 阶段对齐优化、以及最终完整模型三部分。
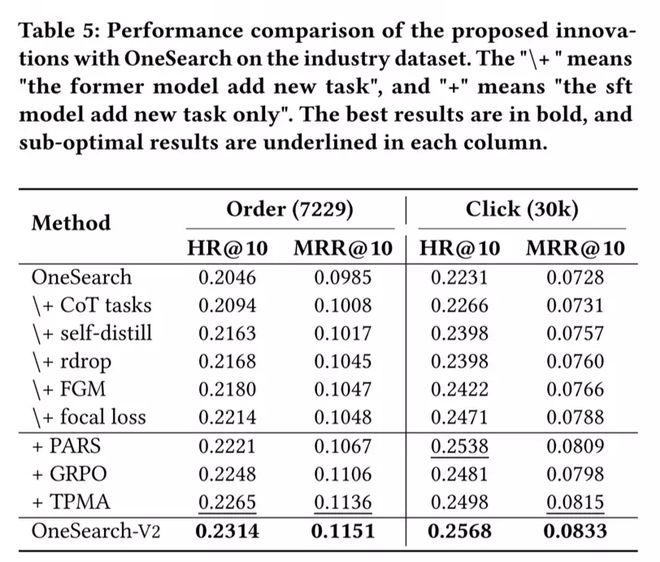
注:"\+" 表示在前一行模型基础上累加新组件(逐步叠加),"+" 表示在 SFT 完成后的模型上单独添加对齐任务。最优结果加粗。
离线实验分析:
3.1.2 消融实验(自蒸馏模型 vs. 独立训练的教师 / 学生模型)
为验证自蒸馏是否真正将推理能力内化进模型权重(而非仅依赖关键词输入),我们对比三种配置:Base (S) 不含关键词训练 + 评估的学生模型,Base (T) 含关键词训练 + 评估的教师模型,以及自蒸馏模型分别在教师端与学生端的评估结果。
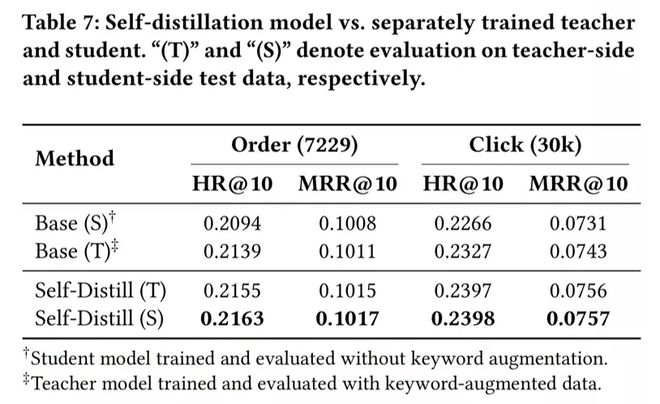
† Student 模型:不含关键词训练和评估。‡ Teacher 模型:含关键词增强数据训练和评估。
消融实验分析:
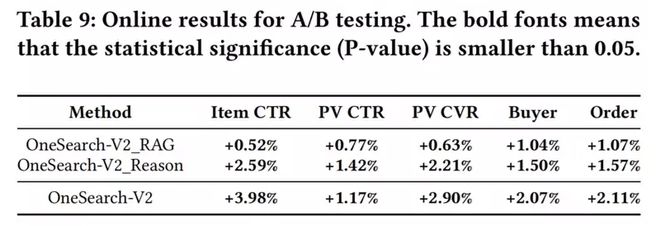
3.2 在线 A/B 测试
为了验证线下收益能否转化为实际的生产价值,我们将 OneSearch-V2 与 V1 进行了严格的 A/B 测试。在关键业务指标方面,OneSearch-V2 取得了统计学意义上的显著提升(p < 0.05):商品点击率提升 3.98%,页面点击率提升 1.17%,页面转化率提升 2.90%,买家数提升 2.07%,订单量提升 2.11%。三个逐步启用的部署版本(V2_RAG、V2_Reason、V2 (full))也呈现清晰的单调递增趋势。
OneSearch V1 OneSearch V2
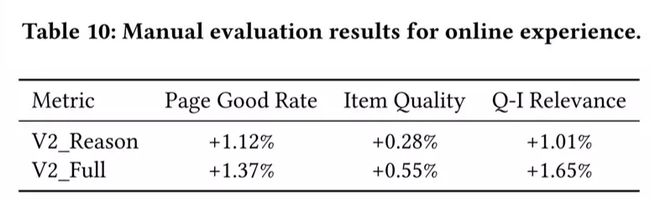
3.3 人工 GSB 评测
对 3,200 个 q-i 查询项对进行人工评估,进一步证实了搜索体验的提升,具体表现为:页面良好率提高了 1.37%,商品质量提高了 0.55%,q-i 相关性提高了 1.65%。
OneSearch V1 OneSearch V2
四、深入分析
4.1 分用户 /query 频次 / 商品冷启动维度下探
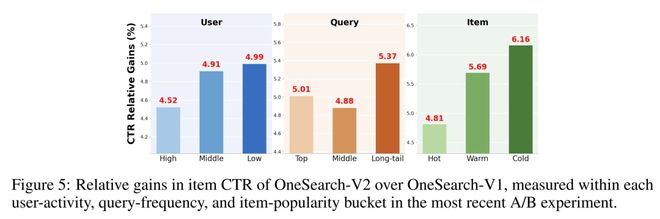
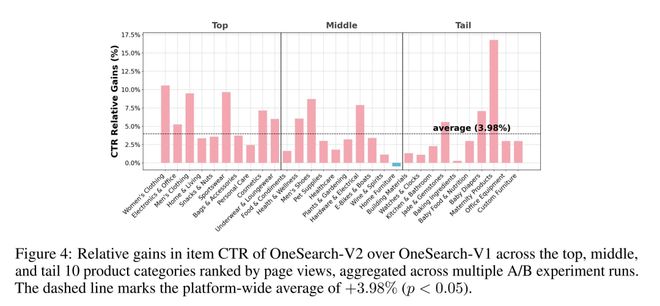
4.2 分行业 CTR 增益分析
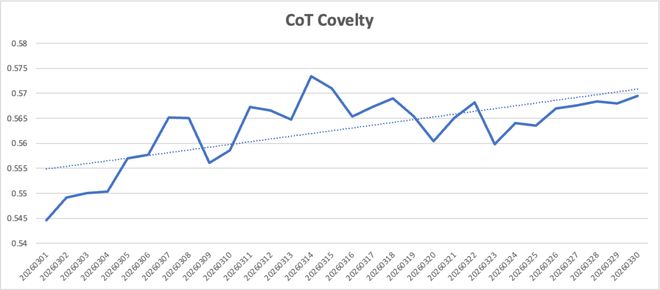
4.3 CoT 关键词覆盖率下钻
4.4 相关性和转化率的 Trade-off

4.5 TPMA 的灵活目标调节能力(3.18 大促实验)
如何针对动态优化目标进行实时干预和自适应训练,一直是生成式检索系统面临的长期挑战。

五、下一步计划
未来方向应遵循三大核心原则:业务需求、场景多样性和以用户为中心的需求。我们发现了几个值得进一步研究的有前景的方向:
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板