西风 发自 凹非寺
量子位 | 公众号 QbitAI
像细菌一样编写代码!
创造出“氛围编程”、“软件3.0”的大神Karpathy又抛出一个新概念,引起网友广泛讨论——
细菌编程(Bacterial code),要有三个特点:代码块小而精、模块化、自包含且易于复制粘贴。
如此一来,开源社区就能通过“水平基因转移”蓬勃发展。
网友们就Karpathy提出的这个新概念进行了广泛讨论。
甚至有网友认为这则推文是他“近十年来看到过的最有趣的帖子”。
还有网友好奇Karpathy的脑洞:
- 老天奶,这些知识是怎么融入你的知识体系的。
Karpathy的新理念,源于对生物演化生存策略的深刻洞察。
他觉得,若想打造一个充满活力、能快速迭代的开源社区,开发者不妨向地球上最具生存智慧的生命形式细菌学习。
这些微观世界的“生存大师”历经亿万年物竞天择,早已将适者生存的法则刻进了基因深处。
不管是极寒、酷热,还是强酸、强碱,乃至太空环境,细菌几乎能殖民地球上所有的生态位,靠的正是其基因组(即“代码”)那套厉害的演化逻辑。
Karpathy把这套演化逻辑提炼成三条法则,还映射到软件开发实践里:
生物学里,复制、维护每个DNA碱基对都得消耗能量。这种“成本约束”,让细菌基因组天然自带“自我精简机制”。
Karpathy觉得,软件开发也该有这意识。写代码太容易、成本太低,大家随手就加依赖,最后代码臃肿不堪,又脆弱又混乱。
细菌的基因,会组织成叫“操纵子(Operon)”的功能簇。这些模块能整体被激活、抑制或转移,实现功能的 “即插即用”。
在编程中,这对应于高内聚、低耦合的模块化设计。每个类或模块都应像一个独立的“操纵子”,可以被轻松地替换或与其它模块组合,而不会引发连锁反应。
咋理解?细菌演化出了“水平基因转移”(Horizontal Gene Transfer)的强大能力,可以直接从其它细菌那里“复制粘贴”有用的基因片段(如抗生素抗性基因),而无需理解对方完整的基因组上下文。
对应到软件开发中,也就是说代码片段应是自包含的,不依赖于项目特定的复杂配置、全局状态或大量的外部库。
更通俗一点,如何判断软件代码是否符合“细菌编程”标准?
就此,Karpathy提出了两个问题:
- 对于你写的任何一个function(基因)或class(操纵子),你能想象有人在不了解你项目其余代码、也无需导入任何新依赖的情况下,直接“顺手牵羊”(yoink)地拿走它,并立即从中获益吗?你的这段代码,有没有潜力成为一个热门的GitHub Gist?
用一句话总结:More gists, less gits.

当然,“细菌编程”并非万能灵药。它虽然擅长快速原型设计,但无法构建复杂生命。
Karpathy表示,相比之下,真核生物基因组是更大、更复杂、组织更紧密的monorepo,创新性明显较低,却是构建完整器官和协调生命活动的必要条件。
凭借智能设计的优势,应该可以兼取两者之长:
- 必要时构建真核生物monorepo骨架,但最大化保留“细菌 DNA”的特性
作为前特斯拉AI总监和OpenAI创始成员,Andrej Karpathy在AI和软件开发领域具有重要影响力。
在提出“细菌编程”之前,还有多个概念被他提出并带火,包括:
软件3.0(Software 3.0)
软件3.0,即用自然语言编程大模型的新时代,这个概念Karpathy在上个月刚刚提出。
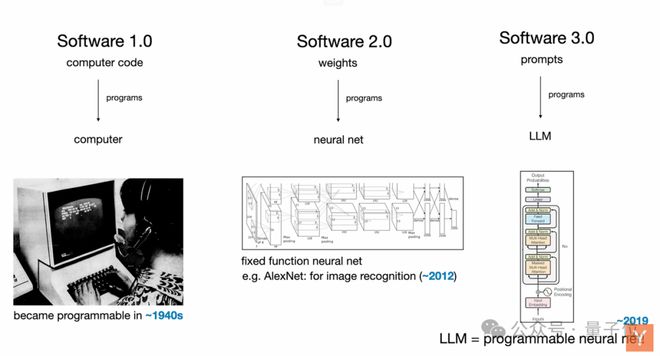
他表示,软件在过去70年基本没怎么变过,但最近几年却连续经历了两次根本性变革。
他认为,当初很多人觉得神经网络就是个分类器,跟决策树差不多,真正的巨变发生在大模型出现后。

- 以前的神经网络都是固定功能的机器,比如AlexNet只能做图像识别。但大模型不一样,它们是可编程的!你的提示词(prompt)就是程序,而且还是用英语(或其他自然语言)写的。
由此,我们现在进入了用自然语言编程大模型的软件3.0新时代。
站在软件3.0的起点,Karpathy对想要进入科技行业的人分享了自己的看法:
- 我们需要重写海量的代码,专业程序员要写,vibe coder也要写。在接下来的十年里,我们会把自主性滑块从左边推到右边。
短期来看,大量软件需重构为 “人类+大模型” 协同模式,半自主应用爆发。
中期来看,大模型逐步渗透企业级工作流,代码、文档、数据分析全面智能化。
长期来看,类似《钢铁侠》贾维斯的智能助手普及,自主权滑动条从左到右延伸,但人类始终是闭环中的决策者。
- 这是一个需要同时掌握 Software 1.0(代码)(模型训练)、3.0(提示词工程)的时代。
氛围编程(Vibe coding)
Vibe coding,是另一个由Karpathy提出的流行词,核心是既然大模型能理解英语,那每个会说话的人都能编程
Karpathy称自己发了推特15年,也猜不到究竟哪条会火,以为随便聊聊Vibe coding这个自己想出来的新词不会有太多人关注,结果这个词现在火到连维基百科页面都有词条了。
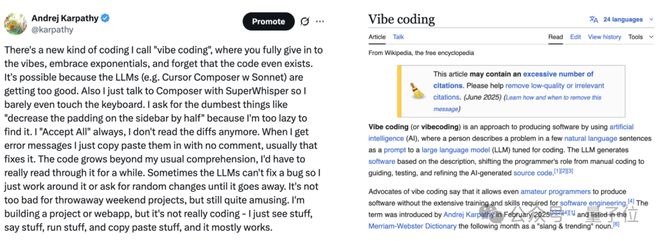
Karpathy自己尝试了Vibe coding,虽然不会Swift,但一天就做出了iOS应用。还做了个叫Menu Genie的餐厅菜单图片生成器。
不过他发现写代码反而是容易的部分,真正困难的是部署——认证、支付、域名配置这些都要在浏览器里点来点去。“计算机在告诉我该点哪里,这太荒谬了,为什么不是它自己去点?”
由此,Karpathy认为:需要为AI agent重建基础设施。
现在的软件都是为人类设计的,到处都是“点击这里”的指令,大模型看不懂。一些先驱如Vercel和Stripe已经开始提供大模型友好的文档,用Markdown格式,把所有“点击”替换成了curl命令。
这就像给网站加robots.txt一样,Karpathy建议加个LLM.txt,直接告诉AI这个网站是干什么的。
另外,还有一个新词,虽然不是Karpathy率先提出的,但得到了他的力挺,这个词就是前几天大火的——上下文工程(Context Engineering)
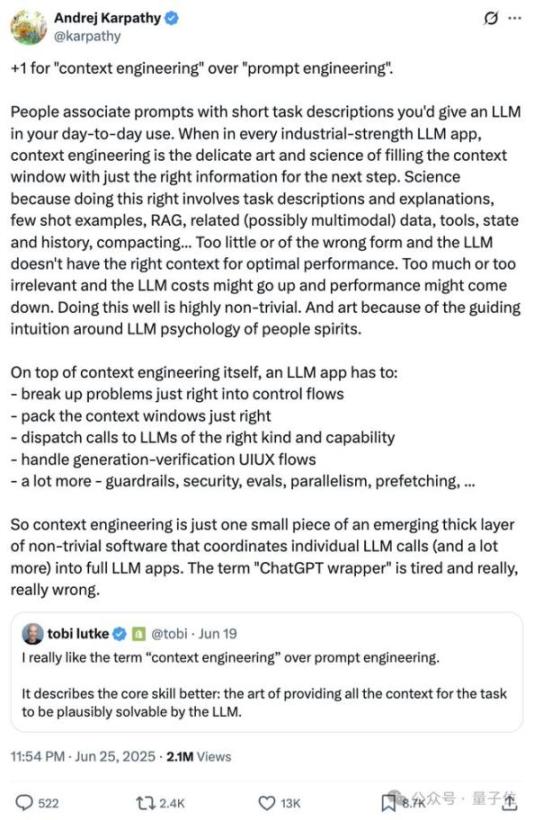
Karpathy表示,很多人觉得提示词就是日常用大模型时输入的简短指令,但在所有工业级LLM应用中,“上下文工程”完全是另一门艺术与科学,它得精准把控上下文窗口里的信息填充。
说它是“科学”,是因为要做好这件事需要整合任务说明、示例演示、检索增强生成(RAG)、相关多模态数据、工具调用、状态记录和历史对话等要素,还要通过压缩技术优化内容。
信息太少或形式不当,LLM 就缺乏足够的上下文来发挥最佳性能;信息过多或无关,则会推高调用成本并降低效果,要做到恰到好处绝非易事。
说它是“艺术”,则因为这需要对LLM的“行为逻辑”有直觉性的把握,如同理解人类思维的规律。
除了上下文工程本身,Karpathy表示,一个LLM应用还需要:
总之,AI的进化速度已经远超预期,而Karpathy的这些脑洞,或许正是未来编程范式的早期信号。

[1]https://x.com/karpathy/status/1941616674094170287
[2]https://x.com/karpathy/status/1937902205765607626
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板