
Angtian Wang 是字节跳动的研究员,研究方向包括视频生成、3D 视觉、differentiable rendering。博士毕业于约翰霍普金斯(Johns Hopkins University)大学。师从 Dr. Alan Yuille。
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。
然而,尽管生成质量不断提升,当前主流方法普遍面临一个关键瓶颈:缺乏有效、直观、用户友好的运动控制方式。
用户在创作动态视频时,往往具有明确的运动意图,例如人物要往哪个方向奔跑、镜头如何推进拉远、动物的跳跃轨迹等。但现有方法普遍依赖于预设模板、动作标签或风格提示,缺少一种既自由又精准的方式来指定对象与摄像机的运动路径。尤其是在存在多个主体或复杂场景交互的情况下,这种控制能力的缺失,极大限制了生成系统的创意表达能力与实际应用价值。
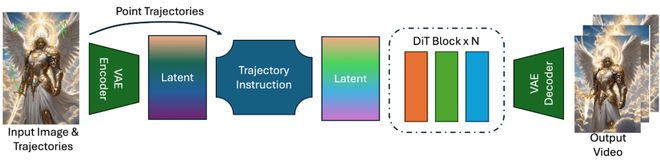
为了解决这一问题,字节跳动提出了ATI——一种全新的、以「轨迹为指令」的可控视频生成框架。ATI 的核心理念是:将用户在输入图像上手绘的任意轨迹,转化为驱动物体与摄像机运动的显式控制信号,并以统一的潜在空间建模方式注入视频生成过程。这使得视频创作从「参数调控」转变为「可视化创意」,让用户「画到哪,动到哪」,以直观方式实现帧级精准控制。

方法
ATI 接受两个基本输入:一张静态图像和一组用户手绘轨迹。这些轨迹可以在图像上自由绘制,支持任意形状,包括直线、曲线、折线、回环乃至抽象形状。ATI 通过高斯运动注入器(Gaussian Motion Injector)将这些轨迹编码为潜在空间中的运动向量,再注入至扩散生成流程中,进而引导生成过程逐帧呈现对应的物体运动与视角变换。
如上图所示,我们希望让视频生成模型「理解」用户画出的运动轨迹,并在后续帧里按照这条轨迹产生动作。为此,我们在模型的输入特征空间上,对每一个轨迹点都注入一个「高斯权重」。使得模型就能在特征图上「看到」一颗颗从时刻 0 到 t 按轨迹移动的小「亮点」,并在训练中逐步理解输入轨迹在输入特征上和 denoise 生成视频的关联。
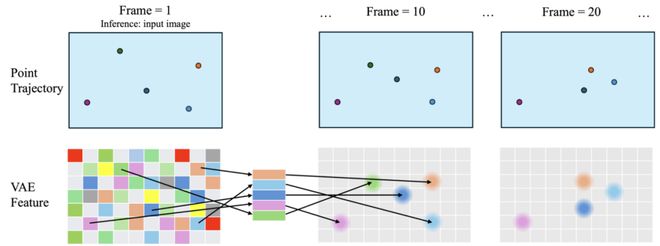
编码图像:先用一个「编码器」把原始图片转换成一张低分辨率的特征图。
采样特征:对于轨迹的起始点,从特征图上精确地(通过双线性差值,保持小数位置精度)取出一个特征向量。
生成高斯权重:在每一帧,对应轨迹点的位置,都用一个小圆形「高斯」亮点去覆盖周围的像素,越靠近圆心的像素,权重越高。
注入特征:把起始点的特征向量,按照这些高斯权重「软」地分配到特征图上的邻近区域,并在模型在生成视频时输入给模型。
这样一来,当我们给生成器喂入图像和这组「高斯掩码+特征」,模型就能直观地「看懂」在每一帧里,哪儿应该动、怎样动,从而生成符合用户手绘轨迹的连贯动画效果。借助高斯运动注入器(Gaussian Motion Injector)与像素级通道拼接策略(Pixel-wise Channel Fusion),ATI 能够统一控制对象级动作、局部身体部位运动与摄像机视角变化,无需切换模型或模块结构,即可高效支持多目标、多风格、多任务的视频生成需求。同时 ATI 支持多个视频生成模型,可以在 Seaweed-7B 以及 Wan2.1-I2V-14B 等不同结构以及大小的模型上均有稳定的表现。
结果展示

用户仅需在原图上以手指或鼠标拖拽绘制任意轨迹,ATI 即可实时捕捉该轨迹路径并将其注入扩散模型。借助高斯运动注入器,无论直线、曲线还是复杂回环,均能被转化为连贯自然的动态视频——画到哪儿,动到哪儿。

在人物或动物肖像场景中,用户可以指定奔跑、跳跃、挥臂等关键动作的轨迹。ATI 对每一帧中的关键点进行细粒度采样与编码,准确还原关节弧度与质心移动,生成符合生物力学规律的自然运动序列。

当场景包含多个目标时,ATI 最多可并行处理 8 条独立轨迹。系统通过空间掩码和通道分离策略,保证各对象身份信息互不干扰,从而呈现复杂群体互动时的连贯动态。

ATI 不仅支持对象级运动控制,还能同步驱动摄像机视角。用户可在原图上绘制推拉、平移、旋转等镜头轨迹,将其与对象轨迹共同注入潜在空间,生成包含摇镜、跟随和俯仰等电影级镜头语言的视频。

在同一推理过程中,物体与摄像机轨迹可同时注入,借助像素级通道拼接策略实现多条运动指令的无缝融合。系统无需模块化切换,即可在潜在特征中并行呈现角色动作、群体互动与镜头切换,输出丰富而连贯的动态叙事。

ATI 展示出良好的跨领域泛化能力,覆盖写实电影、卡通插画、油画质感、水彩渲染、游戏美术等多种艺术风格。通过更换参考图与输入轨迹,系统能够在保留原始风格特征的基础上生成对应的运动视频,满足多元化的应用需求。

用户可在潜在空间中绘制超越物理边界的轨迹,以生成飞天、伸缩、扭曲等非现实动作效果,为科幻或魔幻场景提供无限创意空间。

基于 Wan2.1-I2V-14B 的高精度模型,ATI 可生成与实拍媲美的视频短片,精准还原面部表情、服饰材质与光影细节;同时提供轻量级 Seaweed-7B 版本,以满足资源受限环境中的实时交互需求。
模型开源
目前,ATI 的 Wan2.1-I2V-14B 模型版本已在 Hugging Face 社区正式开源,为研究人员与开发者提供了高质量、可控的视频生成能力。围绕该模型的社区生态也在快速完善:Kijai开发的 ComfyUI-WanVideoWrapper 插件支持 FP8 量化模型(如 Wan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensors),显著降低显存需求,方便在消费级 GPU 上进行推理部署。同时,Benji在 YouTube 发布的教学视频《ComfyUI Wan 2.1 任意轨迹指令运动控制教程》为创作者提供了详尽的实操指南。完整代码与模型请参阅 GitHub(bytedance/ATI)及 Hugging Face 模型库。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板