当 OpenAI 声称其 o3 模型在编程竞赛中达到了 2700+ 的 Elo 评分,足以跻身全球顶尖选手行列时,一群年轻的研究者却给出了截然不同的答案。由多位华人 00 后奥林匹克竞赛获奖者主导、美国纽约大学助理教授谢赛宁参与的研究团队推出了 LiveCodeBench Pro 基准测试,结果让人大跌眼镜:包括最先进的 o3-high、Gemini 2.5 Pro 在内的所有大语言模型,在困难级别的编程问题上无一例外地得了 0 分。
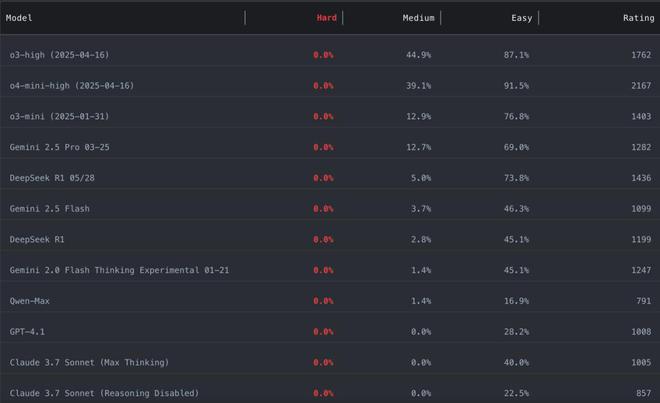
(来源:LiveCodeBench Pro)
这个名为 LiveCodeBench Pro 的测试由来自纽约大学、美国普林斯顿大学、美国加州大学圣地亚哥分校等院校的年轻研究者共同开发。团队的核心成员包括多位在国际信息学奥林匹克竞赛(IOI,International Olympiad in Informatics)中获得奖牌的选手。

图丨相关论文(来源:arXiv)
项目的主要负责人之一 Zihan Zheng 毕业于成都外国语学校,如今是纽约大学的一名本科生。另一位负责人柴文浩(Wenhao Chai)是浙江大学校友,即将前往普林斯顿大学就读博士。还有 Zerui Cheng、Shang Zhou、Zeyu Shen、Kaiyuan Liu 等共同一作也大都是本科或直博在读,甚至 Hansen He 目前还只是一名高中生。

图丨Zihan Zheng(左);柴文浩(右)(来源:LinkedIn)
论文指出,现有的编程评测基准存在明显缺陷,包括测试环境不一致、测试用例薄弱容易出现假阳性、难度分布不平衡,以及无法隔离搜索污染的影响。LiveCodeBench 虽然提供了编程问题,但仍然受到这些问题困扰,而 CodeELO 等框架虽然专注于竞赛编程,但依赖静态档案,难以区分真正的推理能力和记忆能力。
LiveCodeBench Pro 的独特之处在于它的实时性和纯净性。研究团队实时收集来自 Codeforces、国际大学生程序设计竞赛(ICPC,International Collegiate Programming Contest)、IOI 等顶级赛事的最新题目,在任何解答或讨论出现在网络上之前就将其纳入测试集。这种做法有效避免了数据泄露问题,确保模型无法通过记忆训练数据中的答案来“作弊”。
截至 2025 年 4 月 25 日,LiveCodeBench Pro 共收录了 584 道高质量编程题目,完全摒弃了 LeetCode 等相对简单且容易被污染的题源。Zihan Zheng 还表示,每个季度他们都会发布一个全新的评估集,其中包含该季度独有的问题,以最大限度地减少污染并确保最新的基准测试。
测试结果令人相当意外。研究团队将题目按 Codeforces 风格的 Elo 难度分为三个等级:简单(≤2000 分,世界级选手通常 15 分钟内可解)、中等(2000-3000 分,需要融合多种算法和复杂数学推理)、困难(>3000 分,需要极其深刻的推导,连最强选手都可能无法解决)。
在最具挑战性的困难级别上,无论是 OpenAI 的 o3-high、Google 的 Gemini 2.5 Pro,还是 DeepSeek 的 R1 模型,全部交出了 0 分的答卷。即使在中等难度的问题上,表现最好的 o4-mini-high 也只达到了 53.5% 的通过率,而 Gemini 2.5 Pro 仅为 25.4%。
值得注意的是,研究团队计算了模型的 Codeforces 等效 Elo 评分。o4-mini-high 的评分为 2116,虽然听起来不错,但这仅能排在所有人类参赛者的前 1.5%,远达不到“超越精英人类”的水平。OpenAI 宣称的 2719 评分与实际测试结果之间存在约 400 分的差距,研究者推测这主要归因于工具调用和终端访问等外部辅助的作用。
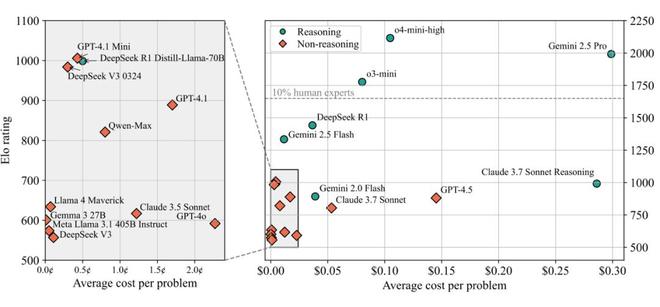
图丨LiveCodeBench Pro 排行榜(来源:arXiv)
为了深入理解模型的能力边界,研究团队创新性地将编程问题按认知重点分为三类。知识密集型问题主要考查对算法模板和数据结构的掌握,这类问题的解答往往需要现成的代码模板,比如快速傅里叶变换的应用。在这类问题上,模型表现相对较好,因为相关内容在训练数据中大量存在。

图丨知识密集型问题示例(来源:arXiv)
逻辑密集型问题需要系统性的数学推理和逐步推导,如组合数学和动态规划,要求将符号操作转化为高效算法。

图丨逻辑密集型问题示例(来源:arXiv)
观察密集型问题则需要从问题描述中敏锐地捕捉关键洞察,往往一个“顿悟”就能让复杂问题迎刃而解。

图丨观察密集型问题示例(来源:arXiv)
测试结果显示,模型在不同类型问题上的表现差异巨大。在线段树、图论、数据结构等知识密集型问题上,多数模型都能达到相当水平,这些问题本质上考验的是代码实现能力和算法库的掌握程度。在组合数学、动态规划等逻辑密集型问题上,模型表现中等,能够进行一定程度的逻辑推理。
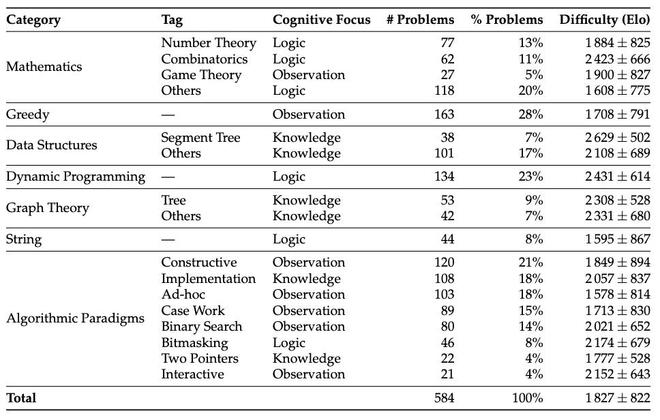
(来源:arXiv)
但在博弈论、贪心算法、构造类等观察密集型问题上,几乎所有模型的 Elo 评分都跌破 1500,表现惨不忍睹。特别是在需要处理边界情况(case work)的问题上,除了 o4-mini-high 外,其他模型的评分都在 1500 以下,显示出模型在识别和处理边界条件方面的显著不足。
研究团队还进行了细致的错误分析,他们逐行对比了 125 个 o3-mini 模型的失败提交和同等水平人类选手的失败提交。结果发现,o3-mini 在算法逻辑错误和错误观察方面的失误比人类多出 34 次,这些是真正的概念性错误,而非表面的程序错误。

图丨比较 o3-mini 和人类提交被拒绝的原因(来源:arXiv)
但在实现层面,o3-mini 的表现明显优于人类,实现逻辑错误比人类少 25 次,所有观察到的初始化错误和输入输出格式错误都出现在人类提交中,模型几乎不会出现“运行时错误”。这说明模型的编程语法和代码实现能力确实不错,但在核心的算法设计和问题理解上存在根本性缺陷。
更要命的是,o3-mini 有 45 次在样例输入上就失败了,而人类选手在提交前通常会先在本地测试样例。这暴露了模型无法有效利用给定信息的问题,连最基本的验证都做不好。与此形成对比的是,具备终端访问和工具调用能力的模型 (如 o3 和 o4-mini-high 的完整版本) 预期会大大减少这类容易发现的错误。
在推理能力的测试中,研究团队专门对比了 DeepSeek V3 与 R1、Claude 3.7 Sonnet 的普通版与推理版之间的差异。结果显示,推理功能在组合数学问题上带来了最大提升,DeepSeek R1 相比 V3 在此类问题上提高了近 1400 个 Elo 点。在数据结构、线段树等知识密集型问题上,推理也带来了显著改善,这符合预期,因为这些问题往往需要结构化思维。但在博弈论、贪心、构造等观察密集型问题上,推理的帮助微乎其微,有时甚至是负面的。这说明当前的链式思考技术虽然能加强逻辑推导,但对培养算法直觉和创造性洞察力作用有限。
业界常用的 pass@k 评估方法允许模型多次尝试同一问题,取最好结果。在 LiveCodeBench Pro 上,这种方法确实能显著提升模型表现。o4-mini-medium 的评分从单次尝试的 1793 提升到 10 次尝试的 2334,类似的提升在其他模型上也很明显。研究发现,在获得最大改善的五个类别中,有三个——博弈论、贪心和边界处理——都属于观察密集型问题,这些问题往往可以通过假设验证来解决,多次尝试大大增加了猜中正确答案的概率。但即使给予多次机会,模型在困难问题上的通过率依然为零,表明这些问题的难点不在于偶然的实现错误,而在于根本性的算法理解缺失。
测试中还发现了一个有趣现象:o4-mini-high 在交互式问题上的表现异常糟糕,Elo 评分跌至 1500 左右,其他模型表现也很差。交互式问题要求程序与评测系统进行多轮信息交换,需要对问题有深刻理解才能设计正确的交互策略。研究团队发现,模型经常因为“空闲时间超限”而失败,说明它们无法理解交互的时机和策略。
从成本角度来看,LiveCodeBench Pro 统计显示,最昂贵的模型未必表现最好。Claude 3.7 Sonnet 推理版平均每题花费 0.29 美元,但 Elo 评分仅为 992,性价比很低。相比之下,一些较便宜的模型反而表现更稳定。o4-mini-high 由于推理链条过长 (最多 10 万 token) 和成本高昂(约 200 美元每次完整测试),研究团队只能限制其在 pass@3 设置下进行评估。
这些发现表明,尽管大语言模型在代码生成和简单编程任务上表现出色,但在需要深度算法思维的复杂问题上仍有很长的路要走。正如论文所指出的,当前模型的高性能很大程度上依赖于实现精度和工具增强,而非卓越的推理能力。在算法创新和问题洞察这些人类智慧的核心领域,AI 仍然无法与顶尖的人类专家相提并论。
参考资料:
1.https://livecodebenchpro.com/
2.https://arxiv.org/abs/2506.11928
运营/排版:何晨龙
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板