
机器一般过质保之后,就会因为各种各样的问题而宕机。而这一次的宕机,让笔者观察到了平常观察不到的tcp在对端宕机情况下的行为。经过详细跟踪分析原因之后,发现可以通过调整内核tcp参数来减少宕机造成的影响。
笔者所在的公司用某个中间件的古老版本做消息转发,此中间件在线上运行有些年头了,大约刚开始部署的时候机器还是全新的,现在都已经过保了。机器的宕机导致了一些诡异的现象。如下图所示:
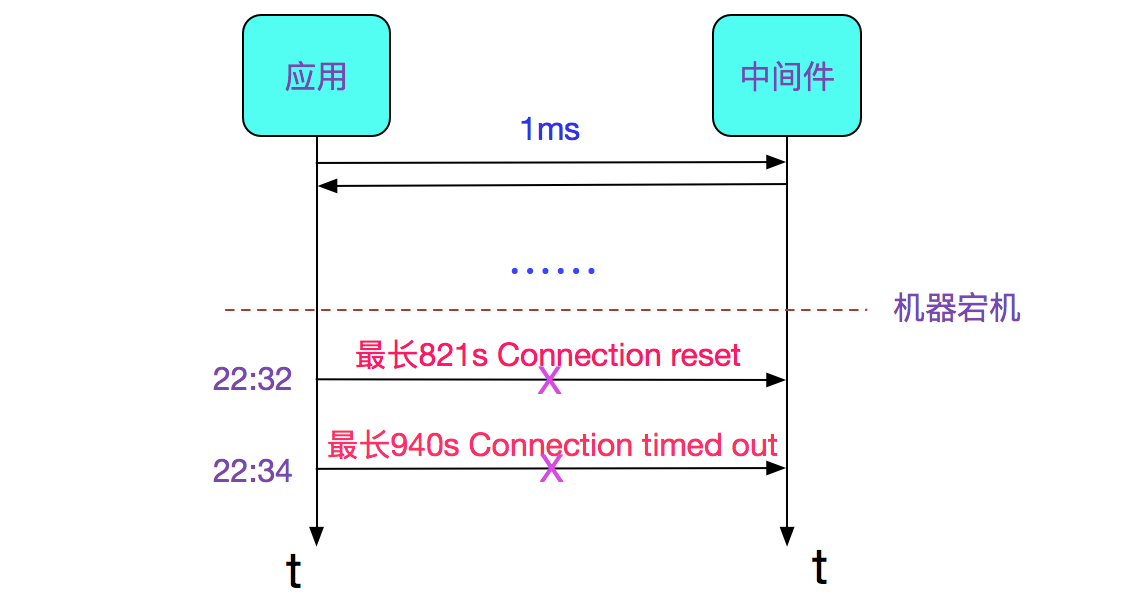
在中间件所在机器宕机之后,出现了调用中间件超时的现象。抛开各种业务细节,会发现出现了时间很长的超时。其中一波在821s之后报出了Connection reset异常,还有一波在940s之后报出了Connection timed out(Read failed)异常。
发现出bug的时间点很微妙,有将近10个请求是在22:32:22.300左右集中报错,并且这个时间点有Connection reset。
另一波是在22:34.11.450左右集中报错,并且这个时间点由Connection timed out(Read failed)。
于是笔者看了下此中间件client的网络模型,如下图所示: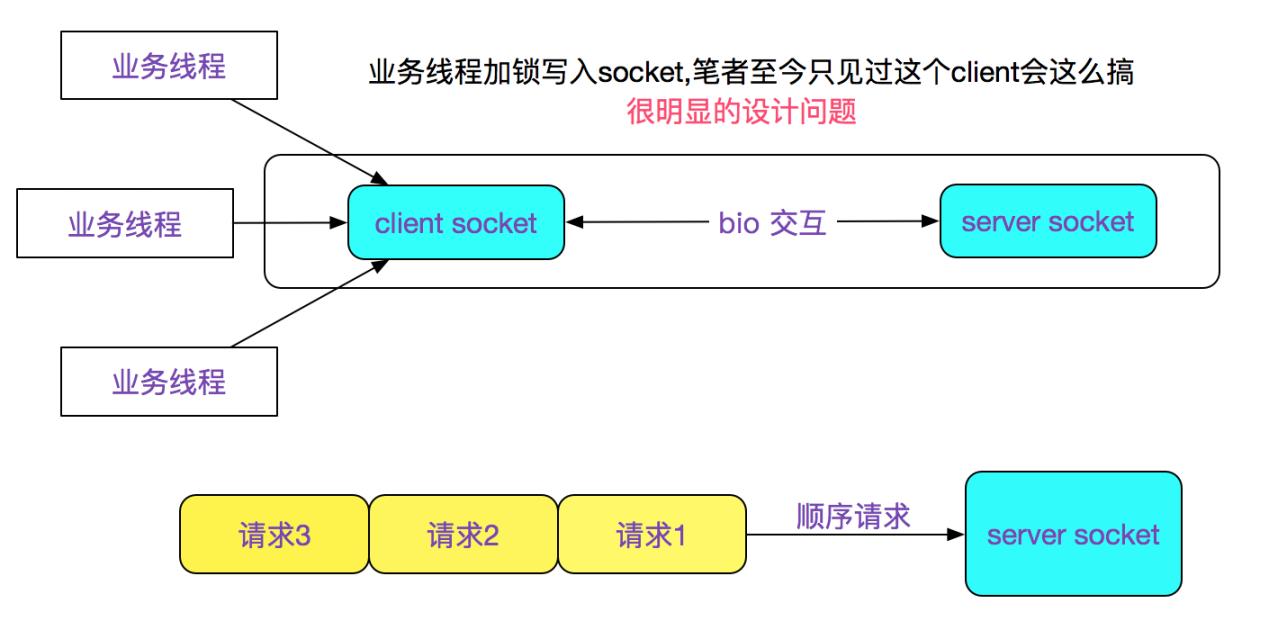
这就很容易理解,为何请求为何都是在同一时刻超时,因为是顺序请求,后面的几个请求还没发送出去,就由于第一个请求超时而导致后面的所有请求报错。如下图所示: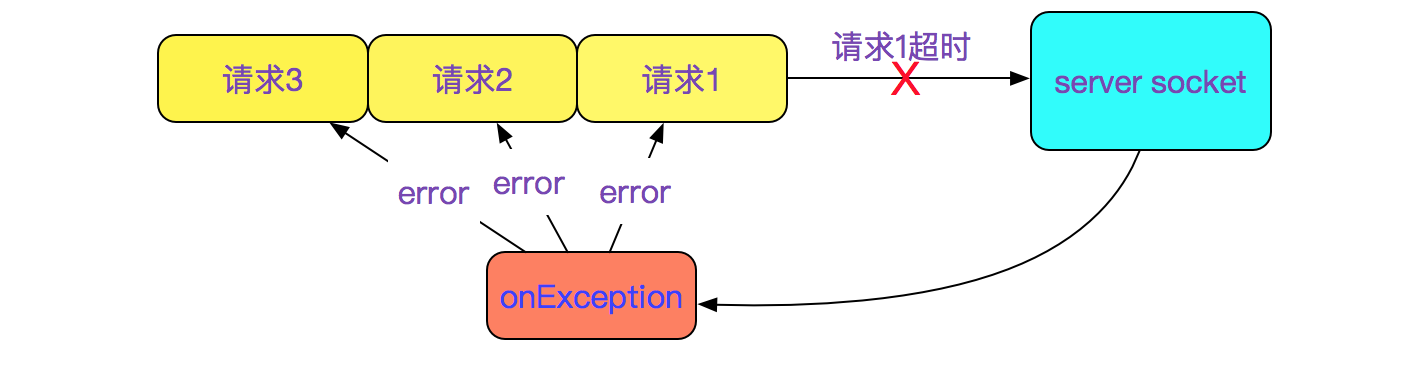
进一步推出,真正的socket超时时间是请求1(最长)的超时时间。
即对应
Connection reset的821s
Connection timed out(Read failed)的940s
这个中间件采用了bio模型,并且socket没有设置超时时间,其业务超时时间通过业务层的future来控制。但是这个超时时间只有在真正发送请求的时间起作用,每个请求之前还会有其它的一段交互,如下图所示: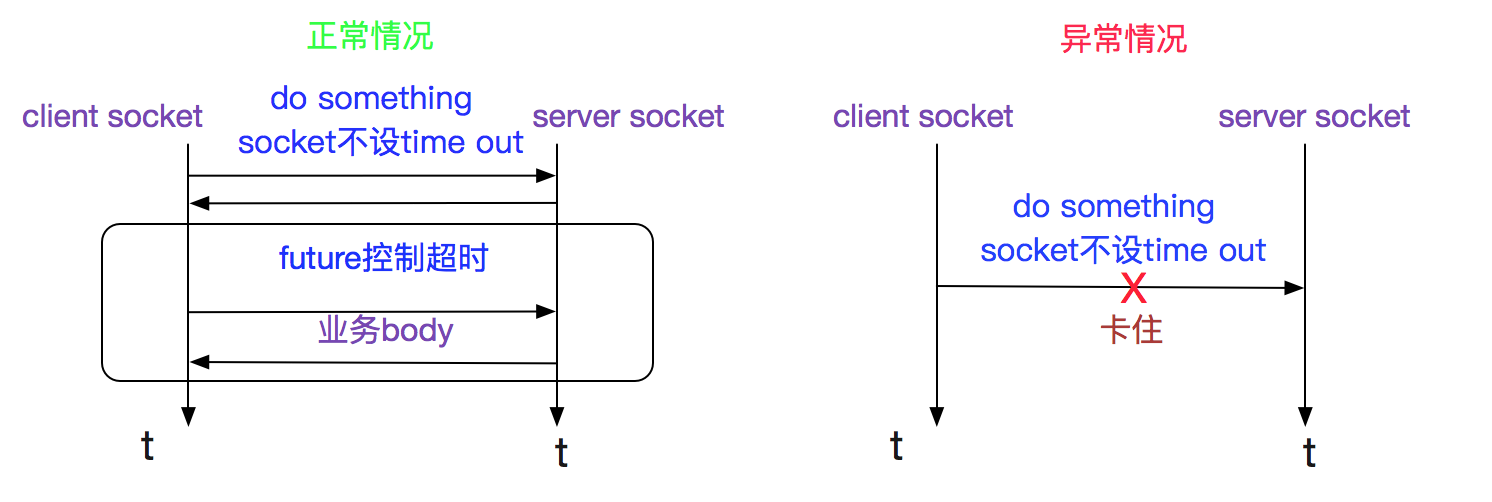
至此,问题原因已经很明显了,在(do something)的那个过程由于socket设置soTimeOut为0,导致卡住了相当长的一段时间。代码如下图所示:
.....
protected int soTimeout;
......
protected void initialiseSocket(Socket sock) throws SocketException, IllegalArgumentException {
......
// 默认是0
sock.setSoTimeout(soTimeout);
......
}
问题本身的查找是比较简单的,如果仅仅只有这些的话,笔者也不会将其写成一篇博客。
由于socket设置timeout(>0)是一种常识,很少遇到设置为0的情况。于是其引起的现象引起了笔者的兴趣。我们看看socket设置timeout为0后jdk源码的描述:
/**
* ......
* A timeout of zero is interpreted as an infinite timeout.
* ......
*/
public synchronized void setSoTimeout(int timeout) throws SocketException {
if (isClosed())
throw new SocketException("Socket is closed");
if (timeout < 0)
throw new IllegalArgumentException("timeout can't be negative");
getImpl().setOption(SocketOptions.SO_TIMEOUT, new Integer(timeout));
}
里面有这么一段话
A timeout of zero is interpreted as an infinite timeout
按上述字母解释为如果设置为0的话,应该是等待无限长的时间(直到进程重启)。
可是按照线上业务的表现,确是有超时时间的,只不过时间很长。最长的达到了940s,即15分钟多。
这就引起了笔者的兴趣,到底是什么让这个无限的超时时间被打断呢?我们继续分析。
首先我们聚焦于第一个异常报错Connection reset(22:32分), 笔者本身阅读过tcp协议栈源码,知道基本上所有Connection reset都由对端发出。所以笔者料定在22:32分的时候,机器肯定又活过来了,但是对应的中间件进程确没有起来,所以没有对应的端口,进而当包过来的时候,发送tcp reset包回去(即使当前中间件起来了也会发送reset,因为tcp本身的seq序列号校验失败)。如下图所示: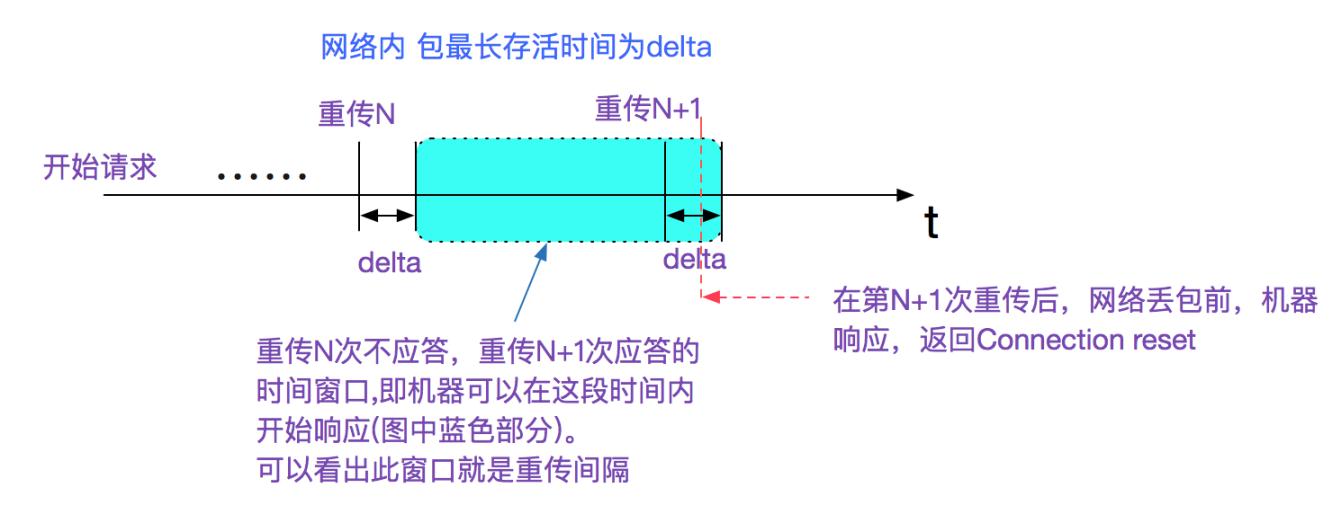
然后了解到在22:32左右,为了拷贝宿主机内部的消息记录,运维确实将宕掉的机器重新给拉起来了,这进一步印证了我的想法。但是按照笔者的推论,在22:32分新发出重传的所有的请求都被Connection reset了,为何在将近两分钟之后(准确的说是在1分49s之后由又报了一波错?)继续往下分析。
(注意22:32分和22:34分报错的是不同的socket连接)
这个错误很少遇到。不知道是在哪种情况下触发。具体的异常栈为:
Caused by: java.net.SocketException: Connection timed out(Read failed)
at java.net.SocketInputStream.socketRead0(Native Method) ~[?1.8.0_121]
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) ~[?:1.8.0_121]
......
于是用sublime搜索Connection timed out,发现其只在Java_java_net_PlainSocketImpl_socketConnect出现,和上面的异常栈明显不符合。
那么就从socketRead0入手,我们详细看看源代码:
JNIEXPORT jint JNICALL
Java_java_net_SocketInputStream_socketRead0(JNIEnv *env, jobject this,
jobject fdObj, jbyteArray data,
jint off, jint len, jint timeout)
{
......
nread = NET_Read(fd, bufP, len);
if (nread <= 0) {
if (nread < 0) {
switch (errno) {
case ECONNRESET:
case EPIPE:
JNU_ThrowByName(env, "sun/net/ConnectionResetException",
"Connection reset");
break;
case EBADF:
JNU_ThrowByName(env, JNU_JAVANETPKG "SocketException",
"Socket closed");
break;
case EINTR:
JNU_ThrowByName(env, JNU_JAVAIOPKG "InterruptedIOException",
"Operation interrupted");
break;
default:
NET_ThrowByNameWithLastError(env,
JNU_JAVANETPKG "SocketException", "Read failed");
}
}
}
......
}
答案就在NET_ThrowByNameWithLastError里面,其最后调用的是os::stderr来获取kernel返回的error字符串。
查了下linux stderr手册,发现是ETIMEDOUT对应了Connection timed out。
但是后面的Connection timed out(Read failed)中的(Read failed)不应该拼接在后面,因为其逻辑是kernel返回error就用kernel的error,否则用defaultDetail即(Read failed和errno的组合)。具体原因,笔者并没有在openJdk源码中找到,猜测可能是版本的原因或者oracleJdk和openJdk之间细微的差别。
既然是linux kernel返回的,笔者就立马翻了linux源码。
(这其中有个插曲,就是笔者一开始看的是2.6.24内核源码,发现怎么计算都对不上数据。后来看到线上用的是2.6.32内核版本,翻了对应版本的源码,才搞定)
既然是sockRead0返回的,那肯定不是socket创建连接阶段(SYN),肯定到了establish的send/rcv阶段。这个错误最有可能就是在重传失败的时候返回的错误。于是翻了下重传的源代码:
static void tcp_retransmit_timer(struct sock *sk)
{
......
// 检查当前重传是否已经超过最大时间
if (tcp_write_timeout(sk))
goto out;
......
icsk->icsk_backoff++;
icsk->icsk_retransmits++;
out_reset_timer:
// 重新重传定时器,rto最大为TCP_RTO_MAX即为120s
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
if (retransmits_timed_out(sk, sysctl_tcp_retries1 + 1))
__sk_dst_reset(sk);
}
上面逻辑是首先判定是否超时,如果未超时则设置下一个超时时间。逻辑如下图所示: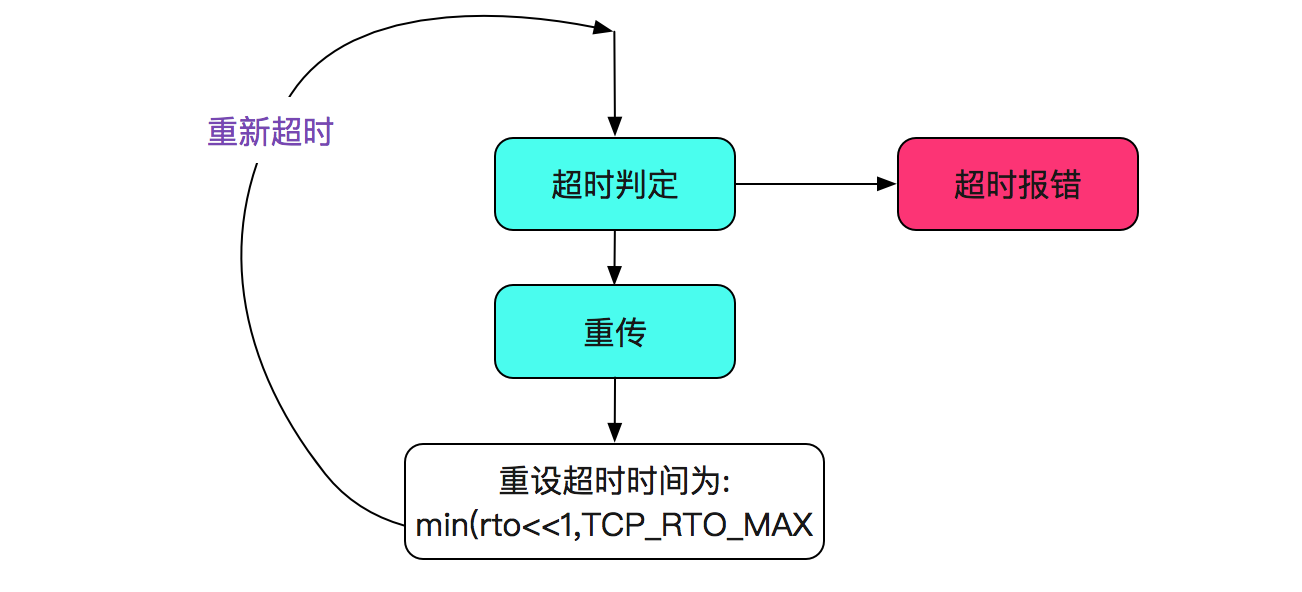
我们再看下tcp_write_timeout:
static int tcp_write_timeout(struct sock *sk){
...
// 对SYN,即创建连接过程中的处理
...
// retry即使kernel中的tcp_retries2
// 即cat /proc/sys/net/ipv4/tcp_retries2即是15
retry_until = sysctl_tcp_retries2;
// 下面就是超时判断的过程
if (retransmits_timed_out(sk, retry_until)) {
/* Has it gone just too far? */
// 如果超过最大时间,则调用tcp_write_err
tcp_write_err(sk);
return 1;
}
return 0;
}
tcp_write_err确实返回了ETIMEDOUT,如下面源码所示:
static void tcp_write_err(struct sock *sk)
{
sk->sk_err = sk->sk_err_soft ? : ETIMEDOUT;
// 返回ETIMEDOUT
sk->sk_error_report(sk);
tcp_done(sk);
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPABORTONTIMEOUT);
}
至此,基本可以判定就是tcp_write_timeout超时了,也即其中的
retransmits_timed_out判定超时。
很明显为什么940s的时候没有Connection reset,就是由于先判断了tcp_write_timeout超时导致没有发送下一个重传包,而直接time_out,如果发了,那就是Connection reset。
这个计算过程直接上源码:
static inline bool retransmits_timed_out(struct sock *sk,
unsigned int boundary)
{
unsigned int timeout, linear_backoff_thresh;
unsigned int start_ts;
if (!inet_csk(sk)->icsk_retransmits)
return false;
if (unlikely(!tcp_sk(sk)->retrans_stamp))
start_ts = TCP_SKB_CB(tcp_write_queue_head(sk))->when;
else
start_ts = tcp_sk(sk)->retrans_stamp;
linear_backoff_thresh =
(TCP_RTO_MAX/TCP_RTO_MIN);
if (boundary <= linear_backoff_thresh)
timeout = ((2 << boundary) - 1) * TCP_RTO_MIN;
else
timeout = ((2 << linear_backoff_thresh) - 1) * TCP_RTO_MIN +
(boundary - linear_backoff_thresh) * TCP_RTO_MAX;
return (tcp_time_stamp - start_ts) >= timeout;
}
上述源码中,boundary = 15,那么
TCP_RTO_MAX=120s,TCP_RTO_MIN=200ms
linear_backoff_thresh = ilog2(120s/200ms)=ilog2(600)=ilog2(1001011000二进制),ilog的实现为:
#define ilog2(n)
( \
__builtin_constant_p(n) ? ( \
(n) < 1 ? ____ilog2_NaN() : \
(n) & (1ULL << 63) ? 63 : \
......
(n) & (1ULL << 9) ? 9 : \
/* 即(1001011000 & 1000000000)=1=>返回9 */
......
)
由于boundary=15 > linear_backoff_thresh(9)所以,计算超时时间为:
timeout = ((2 << linear_backoff_thresh) - 1) * TCP_RTO_MIN +(boundary - linear_backoff_thresh) * TCP_RTO_MAX;
即(TCP_RTO_MIN=200ms,TCP_RTO_MAX=120s)
timeout = ((2 << 9 - 1) * 0.2s + (15 - 9) * 120s=924.6s
值得注意的是,由上面的代码逻辑,我们tcp_retries=15指的并不是重传15次,而是在rto初始值为200ms的情况下计算一个最终超时时间,实际重传次数和15并没有直接的关系。
由上面的计算可知,
即在重传后的tcp_time_stamp(当前时间戳)- start_ts(第一次重传时间戳)>=924.6s的时候,即抛出异常,那么重传最终超时的下界就是924.6s,如下图所示:
我们假设在第N次的时候tcp_time_stamp - start_ts=924.5999s时候进行超时判定,那么势必会进行下一次重传,并在924.5999+120=1044.5999s后超时,如下图所示: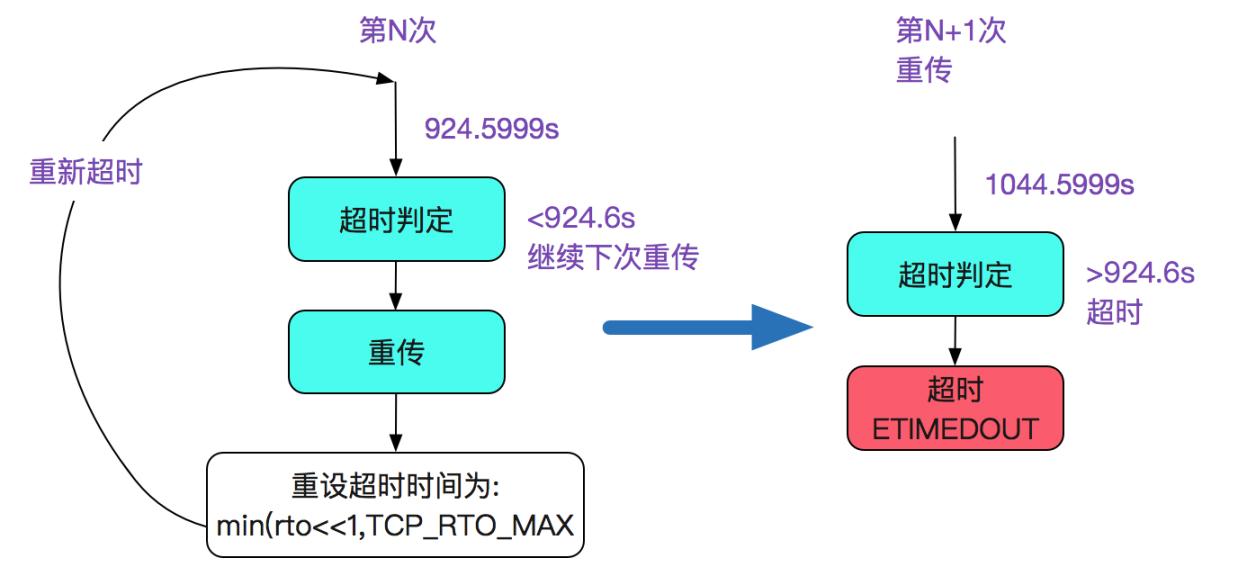
那么,重传最终超时的上界就是1044.6s
最终结论:
重传最终超时的上下界是:
[924.6,1044.6]
由上面代码可知,重传rto是不停的*2,一直到TCP_RTO_MAX(120s)为止,阅读linux代码可知,在笔者的线上情况下,初始rto=srtt>>3 + rttvar(TCP_RTO_MIN)(当然了,实际比这个复杂的多,计算暂以TCP_RTO_MIN代替),即初始rto=200ms+(一个计算出来的值)
笔者写了个模拟程序:
public class RetransSimulate {
public static void timeOutCaclulate(double rto) {
double initialRto = rto;
double sum = 0;
while (true) {
sum += rto;
if (sum > 924600) {
break;
}
rto = rto * 2;
rto = rto < 120000 ? rto : 120000;
}
// 以50ms作为误差
if(Math.abs(sum - 939997) < 50){
System.out.println("rto="+initialRto+",timeout=" + sum);
System.out.println();
}
}
public static void main(String[] args) {
// rtt > 3 + rttval(这个计算有点复杂,这边可以直接用TCP_RTO_MIN做计算)
// 以0.01ms为精度
double rto = 0.01 + 200;// 0.01 for random rtt > 3(初始扰动),200 for TCP_RTO_MIN
// 最多计算到300
for (int i = 0; i < 10000; i++) {
timeOutCaclulate(rto);
rto += 0.01 ;
}
}
}
发现距离线上真实表现超时时间最近的是:
rto=215.00999999998635,timeout=939955.229999986
rto=215.01999999998634,timeout=939965.459999986
rto=215.02999999998633,timeout=939975.689999986
rto=215.03999999998632,timeout=939985.919999986
rto=215.0499999999863,timeout=939996.1499999859
rto=215.0599999999863,timeout=940006.3799999859
rto=215.0699999999863,timeout=940016.609999986
rto=215.07999999998628,timeout=940026.839999986
这样,基本就能基本确定在宕机的时候,用的rto是215了
题外话:
之前博客里面笔者想当然的将rto认为成rtt,导致之前的模拟程序在rto的初始值没有加上200ms,我们同事在复现现场的时候,发现第一次重传包确实是200ms左右,和笔者的推理并不一样。
使得笔者重新阅读了rto源码,发现其rto初始就要加上TCP_RTO_MIN(其实是rttvar,细节有点复杂,在此略过不表),感谢那位同事,也向之前阅读过笔者此篇博客的人道歉,笔者犯了想当然的毛病。
由于到了800s/900s的时候,肯定已经到了TCP_RTO_MAX(120s),所以我们可以根据两个socket的报错时间计算一下机器响应的时间窗口。在这里为了简便分析,我们忽略包在网络中的最长存活时间,如下图所示: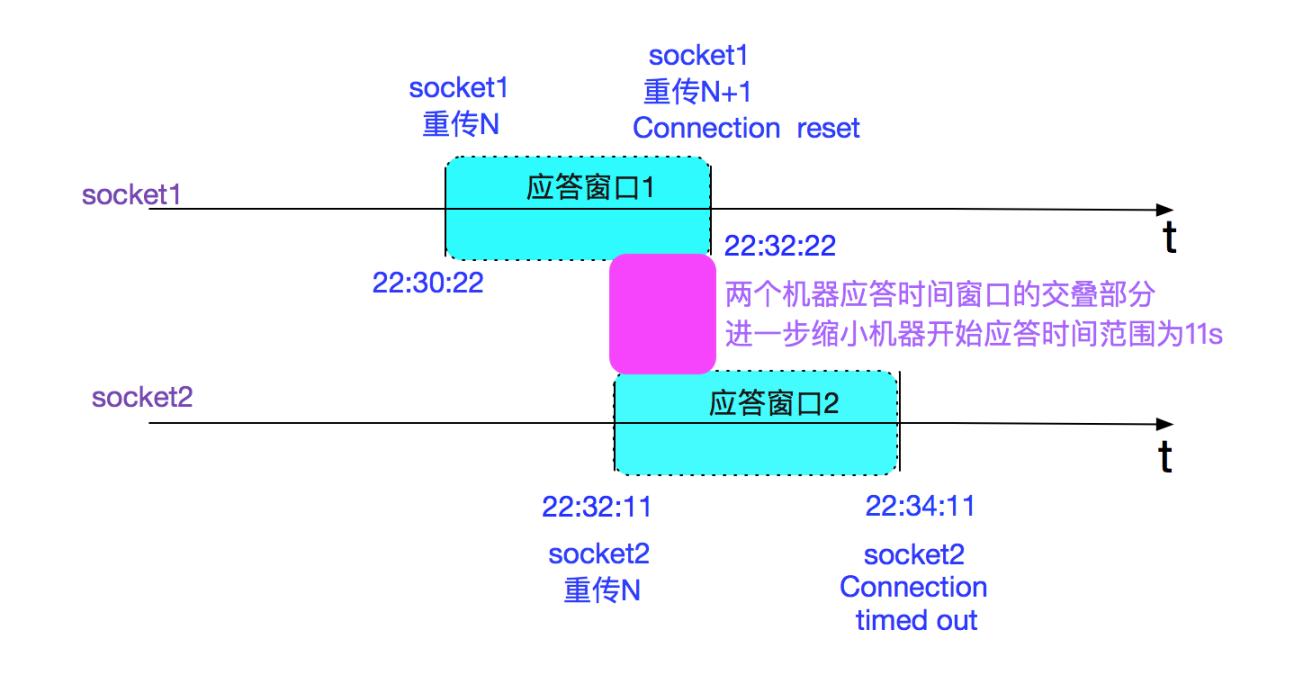
即机器开始应答的时间应该在22:32:11至22:32:22之间。
当然了,很难获取到机器真正开始应答的精确时间来证实笔者的计算。但是这个计算的意义在于如果两者的应答窗口没有交叠,那么笔者的上述推论就是错的,需要推倒重来。存在这个时间窗口,可以让笔者的推测在逻辑上自洽。
将tcp_retries2减少。soTimeOut在这个中间件client代码里面由于其它问题不建议设置。
机器宕机虽然不讨人喜欢,但是观察宕机后线上的种种表现可是一次难得机会,能够发现平时注意不到的坑。另外,定量分析其实蛮有意思的,尤其是种种数据都对上的时刻,挺有成就感_。
转自:https://www.cnblogs.com/alchemystar/p/13704067.html
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板